
/ home / newsletters /
Bitcoin Optech Newsletter #340
今週のニュースレターでは、LDKに影響する脆弱性の修正の発表と、
LNのチャネルアナウンスのゼロ知識ゴシップに関する議論、
最適なクラスターリニアライゼーションの検出に適用できる先行研究の発見、
トランザクションリレーの帯域幅を削減するためのErlayプロトコルの開発に関する最新情報、
LNのエフェメラルアンカーを実装するためのさまざまなスクリプトのトレードオフの検討、
コンセンサスの変更を必要とせずプライバシーを保護する形でOP_RAND opcodeをエミュレートするための提案、
最小トランザクション手数料率の引き下げに関する新たな議論を掲載しています。
ニュース
-
● LDKにおけるチャネル強制閉鎖の脆弱性: Matt Morehouseは、 彼が責任を持って開示し、LDKバージョン0.1.1で修正された LDKに影響する脆弱性についてDelving Bitcoinに投稿しました。 Morehouseが最近開示したLDKの別の脆弱性(ニュースレター #339参照)と同様に、 LDKのコード内のループは、問題を処理した最初の時点で終了し、 同じ問題がさらに発生している場合に処理できなくなっていました。 今回の場合、LDKは保留中のHTLCをチャネルで決済できず、 最終的に誠実な取引相手がチャネルを強制的に閉じてHTLCをオンチェーンで決済することになります。
これは、直接の盗難にはつながらないかもしれませんが、被害者が閉鎖されたチャネルの手数料を支払い、 新しいチャネルを開くために手数料を支払い、被害者が転送手数料を稼ぐ能力を低下させる可能性があります。
Morehouseの優れた投稿では、さらに詳細が説明されており、同じ根本原因による将来のバグを回避する方法を示しています。
-
● LNのチャネルアナウンスのゼロ知識ゴシップ: Johan Halsethは、 提案中のチャネルアナウンスプロトコル1.75の拡張機能を Delving Bitcoinに投稿しました。この拡張機能により、 他のノードはチャネルがファンディングトランザクションによって裏付けされていることを検証でき、 複数の安価なDoS攻撃を防止できますが、どのUTXOがファンディングトランザクションなのかを明かす必要がないため、 プライバシーを強化することができます。Halsethの拡張機能は、utreexoと ゼロ知識(ZK)証明システムを使用する彼の以前の研究(ニュースレター #321参照)に基づいています。 これは、MuSig2ベースのSimple Taproot Channelに適用されます。
議論は、Halsethのアイディアと非プライベートなゴシップの継続使用、 ZK証明を生成するための代替方法のトレードオフに焦点が当てられました。 懸念事項には、すべてのLNノードが証明を迅速に検証できること、 すべてのLNノードが証明システムと検証システムを実装する必要があるため、その複雑さなどが挙がっていました。
この記事の執筆時点では、議論は継続中でした。
-
● 最適なクラスターリニアライゼーションを見つけるための先行研究の発見: Stefan Richterは、1989の研究論文をDelving Bitcoinに投稿しました。 彼が見つけたこの論文には、ブロックに格納された場合に、 トポロジー的に有効なトランザクショングループの最高手数料率のサブセットを、 効率的に見つけるために使用できる実証済みのアルゴリズムがあります。 彼はまた、同様の問題に対する複数のC++の実装も発見しました。 これらのアルゴリズムは、「実際にはさらに高速になるはず」です。
クラスターmempoolに関するこれまでの研究は、 異なるリニアライゼーションを簡単かつ高速に比較し、最適なものを使用できるようにすることに重点が置かれていました。 これにより、高速なアルゴリズムを使用してクラスターを即座にリニアライズし、 より低速だがより最適なアルゴリズムを余剰CPUサイクルで実行できるようになります。 しかし、最大比率のクロージャー問題に対する1989年のアルゴリズム、 あるいはその問題に対する別のアルゴリズムが十分高速に実行できるのであれば、 代わりにそれを常に使用することも可能です。しかしそれが中程度に低速であっても、 余剰CPUサイクルで実行するアルゴリズムとして使用できます。
Pieter Wuilleは、興奮気味に応え、質問を続けました。 彼はまた、Bitcoin Research WeekでのDongning GuoとAviv Zoharとの議論を基に、 クラスターmempoolワーキンググループが開発している新しいクラスターリニアライゼーションアルゴリズムについても 説明しました。 このアルゴリズムは、問題を線型計画法を使って対処できる問題に変換するもので、 高速で実装するのが簡単で、(終了する場合)最適なリニアライゼーションを生成します。 しかし、それが(合理的な時間で)終了することを証明する必要があります。
Bitcoinとは直接関係ありませんが、RichterがDeepSeek LLM推論を使用して1989年の論文を見つけた方法についての 説明は興味深いものでした。
この記事の執筆時点では、議論は継続中で、この問題領域に関する追加の論文が調査されていました。 Richterは、「私たちの問題、またはむしろ source-sink-monotone parametric min-cut と呼ばれるその一般化されたソリューションは、マップの簡素化のためのポリゴン集約や、 コンピュータービジョンにおける他のトピックに応用できるようだ」と書いています。
-
● Erlayの最新情報: Sergi Delgadoは、Bitcoin CoreにErlayを実装するための 過去1年間の研究についてDelving Bitcoinにいくつか投稿しました。彼は、 (fanout と呼ばれる)既存のトランザクションリレーがどのように機能するのか、 そしてErlayがそれをどのように変えようとしているのかについて説明するところから始めました。 彼は、すべてのノードがErlayをサポートするネットワークであっても、 いくつかfanoutが残ると予想されると述べています。これは、 「受信ノードがアナウンスされているトランザクションを知らない限り、set reconciliationよりも効率的でかなり高速」 なためです。
fanoutとreconciliationを組み合わせて使用するには、各メソッドをいつ使用するのか、 どのピアと使用するのかを選択する必要があるため、彼の研究は、最適な選択をすることに焦点を当てています:
-
● トランザクションの知識に基づくフィルタリングでは、 ノードが、ピアが既にトランザクションを持っていることを知っていたとしても、 そのピアをfanout対象に含める必要があるかどうかを検討しています。 たとえば、私たちのノードには10個のピアがあり、その内3個のピアはトランザクションを私たちに通知しています。 トランザクションをさらにfanoutするために3つのピアをランダムに選択する場合、 10個のピアすべてから選択するべきか、それともトランザクションを通知していない7個のピアからだけ選択するべきでしょうか? 驚くべきことに、シミュレーション結果は、「選択肢の間に有意差はない」ことを示しています。 Delgadoはこの驚くべき結果を検討し、すべてのピアから検討する必要がある(つまり、 フィルタリングはしない)と結論づけています。
-
● fanout候補のピアを選択するタイミングは、 ノードがfanoutトランザクションを受信するピア(残りはErlayのreconciliationを使用)をいつ選択すべきかを検討しています。 ここでは、2つのオプションが検討されています。ノードが新しいトランザクションを検証して、 リレー用のキューにいれた直後と、そのトランザクションをリレーするタイミングです(ノードはトランザクションをすぐにはリレーしません。 ネットワークトポロジーを調べてどのノードがトランザクションを発信したかを推測する(これはプライバシーにとってよくありません)のを困難にするため、 ランダムに少しだけ待機します)。シミュレーション結果では、 「有意な違いはない」と示されていますが、「Erlayが部分的にサポートされているネットワークでは、 結果が異なる場合があります」。
-
● fanoutを受け取るピアの数は、 fanoutの比率を検討しています。比率が高いほど、トランザクションの伝播は速くなりますが、 帯域幅の節約は減少します。fanoutの比率のテストに加えて、Delgadoは、 Erlay採用の目標の1つでもあるアウトバウンドピアの数を増やすこともテストしました。 シミュレーションでは、現在のErlayのアプローチでは、現在のアウトバウンドピアの制限(8ピア)を使用した場合、 帯域幅が約35%削減され、アウトバウンドピアを12個にした場合、帯域幅が約45%削減されたことが示されました。 ただし、トランザクションのレイテンシーは約240%増加しています。投稿では、 他の多くのトレードオフがグラフ化されています。結果は、現在のパラメーターを選択するのに役立つだけでなく、 より良いトレードオフを実現できる可能性のある代替fanoutアルゴリズムを評価するのにも役立つと Delgadoは指摘しています。
-
● トランザクションの受信方法に基づいたfanout比率の定義は、 トランザクションを最初に受信したのがfanoutかreconciliationかによって、 fanout比率を調整すべきかどうかを検討しています。さらに、調整する必要がある場合、 どの調整比率を使用すべきか?新しいトランザクションがネットワークを介してリレーされ始めると、 fanoutはより高速で効率的になりますが、トランザクションが既にほとんどのノードに到達した後では帯域幅が無駄になります。 ノードが、トランザクションを既に確認した他のノードの数を直接判断する方法はありませんが、 最初にトランザクションを送信したピアが次のスケジュールされたreconciliationを待つのではなくfanoutを使用した場合、 トランザクションは伝播の初期段階にある可能性が高くなります。このデータを使用して、 そのトランザクションのノード自身のfanout比率を適度に増加させ、伝播を高速化できます。 Delgadoはこのアイディアをシミュレートし、すべてのトランザクションに同じfanout比率を使用するコントロール結果と比較して、 帯域幅が6.5%増加するだけで伝播時間を18%短縮する修正fanout比率を見つけました。
-
-
● LNのエフェメラルアンカースクリプトのトレードオフ: Bastien Teinturierは、既存のアンカーアウトプットの代わりに、 TRUCベースのコミットメントトランザクションのアウトプットの1つとして どのエフェメラルアンカースクリプトを使用するべきかについて Delving Bitcoinで意見を求めました。使用するスクリプトによって、 誰がCPFPによってコミットメントトランザクションを引き上げられるか(およびどんな条件で引き上げることができるか)が決まります。 彼は4つの選択肢を提示しました:
-
● P2A(pay-to-anchor)スクリプトの使用: この場合、オンチェーンサイズは最小ですが、 トリムされたHTLCの金額はすべてマイナーに渡されます(現在行われているのと同じ)
-
● 単一参加者による鍵付きアンカーの使用: この場合、チャネルから閉じられた資金を使用できるようになるまで数十ブロック待つことを自ら受け入れた参加者が、 余剰なトリムされたHTLCを請求できるようになります。チャネルを強制的に閉じたい人は、 どのみちその時間待たなければなりません。ただし、どちらのチャネル参加者も、 チャネル資金のすべてを盗まれることなく、第三者に手数料の支払いを委任することはできません。 あなたと取引相手の両方が余剰金額を請求するために競争する場合、 いずれにせよその金額はすべてマイナーにわたる可能性が高いでしょう。
-
● 2つの鍵付きアンカーの使用: この場合、 各参加者は追加のブロックを待つことなく、余剰なトリムされたHTLCを請求できます。 ただし、委任はできません。チャネルの2人の当事者は、引き続き互いに競争可能です。
投稿への返信で、Gregory Sandersは、異なるスキームを異なるタイミングで使用できると指摘しました。 たとえば、トリムされるHTLCがない時はP2Aを使用し、それ以外の場合は鍵付きアンカーの1つを使用します。 トリムされた金額がダストの閾値を超えた場合、 その金額は、アンカーアウトプットではなくLNのコミットメントトランザクションに追加できます。 さらに、彼は「新たな奇妙さ(取引相手がトリムされた金額を増やし、自らそれを取る誘惑に駆られるかもしれない)」を 生み出す可能性があることを警告しました。David Hardingは、 後の投稿でこのテーマについて補足しました。
Antoine Riardは、マイナーのトランザクションのPinningを助長するリスクがあるため、 P2Aを使用しないよう警告しました(ニュースレター #339参照)。
この記事の執筆時点では、議論は継続中でした。
-
-
● OP_RANDのエミュレート: Oleksandr Kurbatovは、 2者のどちらも予測できない方法で支払いを行うコントラクトを作成できるようにする対話型のプロトコルについて Delving Bitcoinに投稿しました。これは機能的にはランダムに支払うのと同等です。 Bitcoinでの 確率的な支払い に関するこれまでの研究では高度なスクリプトが使用されていましたが、 Kurbatovのアプローチでは、勝者がコントラクトの資金を使用できる特別に構築された公開鍵を使用します。 これはよりプライベートで、柔軟性が高くなる可能性があります。
Optechでは、プロトコルを完全に分析することはできませんでしたが、明確な問題は見つかりませんでした。 このアイディアについてさらに議論されることを期待しています。確率的な支払いには複数の用途があり、 これにはトリムされたHTLCなど、 通常は経済的ではない金額をユーザーがオンチェーンで送信できるようにすることなどが含まれます。
-
● 最小トランザクションリレー手数料率の引き下げに関する議論: Greg Tonoskiは、デフォルトの最小トランザクションリレー手数料率の引き下げについて Bitcoin-Devメーリングリストに投稿しました。このトピックは、 2018年から繰り返し議論され(Optechで要約されています)、最近では2022年に議論されました(ニュースレター #212参照)。 注目すべきは、最近開示された脆弱性(ニュースレター #324参照)により、 過去に設定を下げたユーザーやマイナーに影響を与える可能性のある潜在的な問題が明らかになったことです。 Optechは、さらに重要な議論がある場合は更新情報を提供します。
コンセンサスの変更
Bitcoinのコンセンサスルールの変更に関する提案と議論をまとめた月次セクション
-
● クリーンアップソフトフォーク提案の更新: Antoine Poinsotは、コンセンサスクリーンアップソフトフォークに関するスレッドに パラメーターの変更の提案をいくつか投稿しました:
-
● レガシーインプットsigops制限の導入: プライベートスレッドで、 Poinsotと他の何人かのコントリビューターは、(segwit以前の)レガシートランザクションの検証における 既知の問題を使用して検証に長い時間がかかるregtest用のブロックの作成を試みました。 調査の結果、彼は「2019年に最初に提案された緩和策(ニュースレター #36参照 )の下でワーストブロックを有効なものに適応させる」ことができることを発見しました。 これにより、彼は別の緩和策を提案しました。レガシートランザクションの署名操作(sigops)の最大数を2,500に制限します。
OP_CHECKSIGの実行ごとに1 sigopsとしてカウントされ、OP_CHECKMULTISIGの実行ごとに最大20 sigops(使用される公開鍵の数によって変わります)としてカウントされます。 彼の分析によると、これにより最悪の場合の検証時間が97.5%短縮されます。この種の変更の場合と同様に、新しいルールによって以前署名されたトランザクションが無効になるため、 誤って没収されるリスクがあります。 2,500を超えるシングルシグの操作、 または2,125個の鍵を超えるマルチシグ操作1を含むトランザクション必要とする人を知っている場合は、 Poinsotまたは他のプロトコル開発者に通知してください。
-
● タイムワープの猶予期間を2時間に延長: これまで、クリーンアップ提案では、新しい難易度期間の最初のブロックのブロックヘッターの時間は 前のブロックの時間より600秒以上前になることを許可されていませんでした。 つまり、一定量のハッシュレートでは、タイムワープ脆弱性を利用して 10分に1回より速くブロックを生成できませんでした。
Poinsotは、現在、7,200秒(2時間)の猶予期間の使用を受け入れています。これは、 Sjors Provoostが当初提案したように、マイナーが誤って無効なブロックを生成する可能性がはるかに低いためです。 ただし、ネットワークのハッシュレートの50%以上を制御する忍耐強い攻撃者が、 実際のハッシュレートが一定または増加している場合でも、 数ヶ月にわたってタイムワープ攻撃を使用して難易度を下げることができます。 これは公に確認できる攻撃で、ネットワークは対応に数ヶ月かかるでしょう。 Poinsotは以前の議論を要約し(より簡単な詳細の要約はニュースレター #335参照)、 「猶予期間の延長に賛成する論拠はかなり弱いが、そうすることのコストは(安全側に回ることを)禁止するものではない」と 結論づけています。
猶予期間の延長について議論するスレッドで、開発者のZawyとPieter Wuilleは、 難易度をゆっくりと最小値まで下げることができるように見える600秒の猶予期間が、 実際には1回以上の小さな難易度低下を防ぐのに十分であったことを議論しました。 具体的には、Bitcoinの難易度調整バグ(off-by-one)とアーラン分布の非対称性が 難易度の正確な再ターゲットに与える影響について調査しました。 Zawyは「アーランと「2015 hole」の両方の調整が必要ないということではありません。 前のブロックの600秒前が600秒の嘘ではなく、その600秒後のタイムスタンプを期待したため1,200秒の嘘になったのです」 と簡潔に結論づけました。
-
● 重複トランザクションの修正: 重複トランザクション問題に対するコンセンサスソリューションの 潜在的な悪影響に関するマイナーへのフィードバック要請(ニュースレター #332参照)を受けて、 Poinsotはクリーンアップ提案に含める特定のソリューションを選択しました。 各コインベーストランザクションのタイムロックフィールドに前のブロック高を含めるよう求めます。 この提案には2つの利点があります。 スクリプトを解析せずにブロックからコミットされたブロックの高さを抽出できることと、 ブロック高のコンパクトなSHA256ベースの証明を作成できることです(最悪の場合でも約700バイトで、 高度な証明システムがない場合に現在必要となる最悪の場合の1MBの証明よりもはるかに少ない)。
この変更は一般ユーザーには影響しませんが、 最終的にはマイナーがコインベーストランザクションを生成するために使用するソフトウェアを更新する必要があります。 この提案に懸念があるマイナーは、Poinsotまたは他のプロトコル開発者に連絡してください。
Poinsotはまた、彼の研究と提案の現在の状況に関するハイレベルな更新をBitcoin-Devメーリングリストに投稿しました。
-
-
● Braidpoolをサポートするコベナンツの設計のリクエスト: Bob McElrathは、 コベナンツの設計に取り組んでいる開発者に、 彼らのお気に入りの提案や新しい提案が、効率的な分散型マイニングプールの作成を どのように支援できるかの検討の要請をDelving Bitcoinに投稿しました。 Braidpoolの現在のプロトタイプの設計では、署名者のフェデレーションが使用され、 署名者はプールへのハッシュレートの貢献に基づいて閾値署名のシェアを受け取ります。 この場合、多数派のマイナー(または多数派を構成する複数のマイナーの共謀)が、 小規模なマイナーへの支払いを盗むことができます。McElrathは、 各マイナーが貢献に応じてプールから資金を引き出せるようにするコベナンツの使用を希望しています。 彼は、投稿で具体的な要件のリストを示しており、不可能性の証明も歓迎しています。
この記事の執筆時点では、返信はありませんでした。
-
● コミットされたmempoolからの決定論的なトランザクションの選択: 2024年4月のスレッドが先月、新たな注目を集めました。以前、Bob McElrathは、 マイナーにmempoolのトランザクションにコミットさせ、その後、 以前のコミットメントから決定論的に選択されたトランザクションのみをブロックに含めることを許可するという 投稿をしました。彼は2つの用途を考えています:
-
すべてのマイナーに対するグローバル展開: これにより、マイナーが法律、規制およびリスク管理者のアドバイスに従う必要があることが多い世界で、 「トランザクションの選択のリスクと責任」が排除されます。
-
単一のプールに対するローカル展開: グローバルな決定論的アルゴリズムの利点のほとんどを備えていますが、実装にコンセンサスの変更は必要ありません。 さらに、Braidpoolなどの分散型マイニングプールのピア間の帯域幅を大幅に節約できます。 アルゴリズムによって候補ブロックに含めるトランザクションが決定されるため、 そのブロックで生成されたシェアは、プールピアにトランザクションデータを明示的に提供する必要がありません。
Anthony Townsは、グローバルなコンセンサスの変更オプションの潜在的な問題をいくつか説明しました。 トランザクションの選択を変更するにはコンセンサスの変更(おそらくハードフォーク)が必要であり、 非標準トランザクションを作成した人は、マイナーの協力があってもそれをマイニングすることができません。 過去数年間のコンセンサスの変更を必要とするポリシーの変更には、 TRUC、更新されたRBFポリシー、 エフェメラルアンカーが含まれます。Townsは、 数百万ドル相当の価値が誤って非標準のスクリプトにスタックされ、 協力的なマイナーがそれを解除できたという有名なケースをリンクしました。
残りの議論は、Braidpool用に考案されたローカルアプローチに焦点が当てられました。 異論はなく、難易度調整アルゴリズムに関するトピック(次の項目を参照)に関する追加の議論では、 トランザクション選択の決定性によって帯域幅、レイテンシーおよび検証コストが大幅に削減される、 Bitcoinよりもはるかに高いレートでブロックを作成するプールにとって特に役立つ可能性があることが示されました。
-
-
● DAGブロックチェーン用の高速な難易度調整アルゴリズム: 開発者のZawyは、有向非巡回グラフ(DAG)型ブロックチェーンのマイニングの 難易度調整アルゴリズム(DAA)についてDelving Bitcoinに投稿しました。 このアルゴリズムは、Braidpoolのピアのコンセンサス(グローバルなBitcoinのコンセンサスではなく)で使用するために設計されましたが、 議論ではグローバルコンセンサスの側面に繰り返し触れました。
Bitcoinのブロックチェーンでは、各ブロックは1つの親にコミットします。 複数の子ブロックが同じ親にコミットする場合がありますが、 ノードによって ベストブロックチェーン 上で有効とみなされるのはそのうちの1つだけです。 DAGブロックチェーンでは、各ブロックは1つ以上の親にコミットし、 親にコミットする子ブロックは0個以上である場合があります。DAGのベストブロックチェーンでは、 同じ世代の複数のブロックが有効とみなされる場合があります。
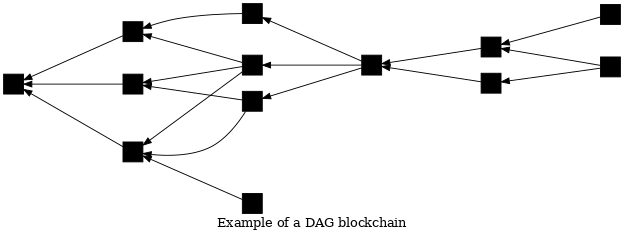
提案されたDAAは、最後に確認された100個の有効なブロック内の親の平均数をターゲットにしています。 親の平均数が増加すると、アルゴリズムは難易度を上げます。親が少ないと難易度は下がります。 Zawyによると、平均2つの親をターゲットにすると、最も速いコンセンサスが得られます。 BitcoinのDAAとは異なり、提案されたDAAでは時間を意識する必要はありません。 ただし、同じ世代の他のブロックよりも大幅に遅れて到着するブロックをピアは無視する必要があります。 遅延についてコンセンサスを得ることは不可能であるため、最終的には、 PoW(proof-of-work)が多いDAGの方がPoWが少ないDAGよりも好まれます。 DAAの開発者であるBob McElrathは、この問題と可能な緩和策を分析しました。
Pieter Wuilleは、この提案はAndrew Millerの2012年のアイディアに似ていると コメントしました。Zawyもこれに同意し、 McElrathは引用を加えて論文を更新する予定です。Sjors Provoostは、 Bitcoin Coreの現在のアーキテクチャでDAGチェーンを処理する複雑さについて説明しましたが、 libbitcoinを使用するのがより簡単で、utreexoを使用すると効率的かもしれないと指摘しました。 Zawyは、プロトコルを徹底的にシミュレートし、プロトコルのさまざまなバリエーションについて、 追加のシミュレーションを行い、トレードオフの最適な組み合わせを見つけようとしていることを示しました。
議論のスレッドの最後の投稿は、この概要が書かれる約1ヶ月前のものでしたが、 ZawyとBraidpoolの開発者は引き続きプロトコルの分析と実装を行っていると思われます。
リリースとリリース候補
人気のBitcoinインフラストラクチャプロジェクトの新しいリリースとリリース候補。 新しいリリースにアップグレードしたり、リリース候補のテストを支援することを検討してください。
-
● BDK Wallet 1.1.0は、Bitcoin対応アプリケーションを構築するためのこのライブラリのリリースです。 デフォルトでトランザクションバージョン2を使用します(相対的ロックタイムのサポートにより バージョン2トランザクションを使用する必要がある他のウォレットとBDKのトランザクションが混ざるようにすることで プライバシーが向上します。ニュースレター #337参照)。 また、コンパクトブロックフィルターのサポートも追加されています( ニュースレター #339参照)。さらに「さまざまななバグ修正と改善」がされています。
-
● LND v0.18.5-beta.rc1は、この人気のLNノード実装のマイナーバージョンのリリース候補です。
注目すべきコードとドキュメントの変更
最近のBitcoin Core、Core Lightning、Eclair、LDK、 LND、libsecp256k1、Hardware Wallet Interface (HWI)、Rust Bitcoin、BTCPay Server、BDK、Bitcoin Improvement Proposals(BIP)、Lightning BOLTs、 Bitcoin InquisitionおよびBINANAsの注目すべき変更点。
-
● Bitcoin Core #21590は、libsecp256k1の実装を基に、 32-bitと64-bitの両方のアーキテクチャのサポートを追加し、特定のモジュラスに特化しながら、 MuHash3072用のsafegcdベースのモジュラ逆数アルゴリズム実装します( ニュースレター#131および#136参照)。 ベンチマークの結果では、x86_64で約100倍のパフォーマンス向上が見られ、 MuHashの計算が5.8msから57μsに短縮され、より効率的な状態の検証が可能になりました。
-
● Eclair #2983は、再接続時のルーティングテーブルの同期を変更し、 チャネルアナウンスをノードのトップピア(共有するチャネルキャパシティによって決定)とのみ同期し、 ネットワークのオーバーヘッドを削減します。さらに、 同期ホワイトリスト(ニュースレター#62参照)のデフォルトの動作が更新されました。 ホワイトリストに登録されていないピアとの同期を無効にするには、 ユーザーは
router.sync.peer-limitを0に設定する必要があります(デフォルト値は5)。 -
● Eclair #2968は、公開チャネルでのスプライシングのサポートを追加します。 スプライシングトランザクションが承認され、両サイドでロックされると、 ノードはアナウンスの署名を交換し、
channel_announcementメッセージをネットワークにブロードキャストします。 最近、Eclairは、このPRの準備としてサードパーティのスプライシングの追跡を導入しました(ニュースレター#337参照)。 このPRでは、プライベートチャネルでのルーティングでのshort_channel_idの使用も禁止され、 代わりにscid_aliasが優先され、チャネルのUTXOが明らかにされないようにします。 -
● LDK #3556は、HTLCの有効期限が近すぎる場合は、上流のオンチェーンの請求の承認を待つ前に、 HTLCを積極的に後方で失敗させることで、HTLCの処理を改善します。これまでは、 ノードは後方のHTLCの失敗をさらに3ブロック遅らせ、請求に承認時間を与えていました。ただし、 この遅延により、チャネルが強制的に閉じられるリスクがありました。さらに チャネルステートをクリーンアップするために
historical_inbound_htlc_fulfillsフィールドが削除され、 インバウンドチャネルでの重複HTLC IDによる混乱を排除するために新しくSentHTLCIdが導入されました。 -
● LND #9456は、次のリリース(0.21)での削除に備えて、
SendToRoute、SendToRouteSync、SendPayment、SendPaymentSyncエンドポイントに 非推奨の警告を追加します。ユーザーは、新しいv2メソッドSendToRouteV2、SendPaymentV2、TrackPaymentV2に移行することをお勧めします。
Footnotes
-
P2SHと提案されているインプットのsigopカウントでは、16個以上の公開鍵を持つ
OP_CHECKMULTISIGは、 20 sigopsとカウントされるので、誰かが毎回17個の鍵で125回OP_CHECKMULTISIGを使用すると、 2,500 sigopsとカウントされます。 ↩