
/ home / newsletters /
Bitcoin Optech Newsletter #340
Der Newsletter der Woche gibt bekannt, dass in LDK eine zuvor
entdeckte Sicherheitslücke erfolgreich behoben wurde, fasst die
Diskussion über Zero-Knowledge-Gossip für LN-Kanalankündigungen
zusammen, beschreibt die Entdeckung früherer Forschungsergebnisse,
die zur Suche nach optimalen Cluster-Linearisierungen angewendet
werden können, liefert ein Update zur Entwicklung des Erlay-Protokolls
zur Reduzierung der Transaktions-Relay-Bandbreite, erörtert die
Vor- und Nachteile verschiedener Skripte zur Implementierung von
LN-Ephemeral-Ankern, leitet einen Vorschlag zur Emulation eines
OP_RAND-Opcodes unter Wahrung der Privatsphäre ohne erforderliche
Konsensänderungen weiter und verweist auf die erneute Diskussion
über die Senkung des Mindesttransaktions-Feerates.
News
-
● Sicherheitslücke bei Channel-Force-Closure in LDK: Matt Morehouse veröffentlichte auf Delving Bitcoin eine Sicherheitslücke, die LDK betrifft und die er verantwortungsvoll offengelegt hat; diese wurde in LDK-Version 0.1.1 behoben. Ähnlich wie Morehouses kürzlich offengelegte Sicherheitslücke in LDK (siehe Newsletter #339), beendete eine Schleife in LDKs Code ihre Ausführung beim ersten Umgang mit einem ungewöhnlichen Ereignis, was verhinderte, dass sie weitere Vorkommen desselben Problems bearbeitete. In diesem Fall konnte dies dazu führen, dass LDK ausstehende HTLCs in offenen Kanälen nicht abbuchte, was letztlich dazu führte, dass ehrliche Kontrahenten die Kanäle zwangsweise schlossen, um die HTLCs on-chain abzuwickeln.
Dies hätte wahrscheinlich nicht direkt zu einem Diebstahl geführt, hätte aber zur Folge gehabt, dass das Opfer Gebühren für die geschlossenen Kanäle, für die Eröffnung neuer Kanäle sowie eine verminderte Fähigkeit zur Erzielung von Weiterleitungsgebühren in Kauf nehmen müsste.
Morehouses hervorragender Beitrag geht detailliert auf weitere Aspekte ein und schlägt vor, wie zukünftige Fehler, die auf dieselbe zugrunde liegende Ursache zurückzuführen sind, vermieden werden können.
-
● Zero-Knowledge-Gossip für LN-Kanalankündigungen: Johan Halseth veröffentlichte auf Delving Bitcoin eine Erweiterung des vorgeschlagenen 1.75 Kanalankündigungsprotokolls, die es anderen Knoten ermöglichen würde, zu überprüfen, ob ein Kanal durch eine Finanzierungstransaktion unterstützt wird, ohne kostengünstige DoS-Angriffe zuzulassen, jedoch ohne zu offenbaren, welche UTXO die Finanzierungstransaktion darstellt – wodurch die Privatsphäre gewahrt bleibt. Halseths Erweiterung greift auf seine vorherige Forschung zurück (siehe Newsletter #321), in der Utreexo und ein Zero-Knowledge- (ZK-) Beweissystem verwendet wurden. Sie soll auf MuSig2-basierte einfache Taproot-Kanäle angewendet werden.
Die Diskussion konzentrierte sich auf die Abwägungen zwischen Halseths Vorschlag, der weiterhin auf nicht-private Gossip setzt, und alternativen Methoden zur Erzeugung des ZK-Beweises. Dabei wurden Bedenken hinsichtlich der schnellen Verifizierbarkeit der Beweise durch alle LN-Knoten und der Komplexität des Beweis- und Verifizierungssystems geäußert, da alle LN-Knoten diese implementieren müssten.
Die Diskussion war zum Zeitpunkt der Erstellung dieser Zusammenfassung noch im Gange.
-
● Entdeckung vorheriger Forschung zur Ermittlung optimaler Cluster-Linearisierung: Stefan Richter veröffentlichte auf Delving Bitcoin einen Forschungsbericht aus dem Jahr 1989, den er gefunden hatte, in dem ein bewährter Algorithmus vorgestellt wird, der verwendet werden kann, um effizient den höchstbezahlten Teil einer Gruppe von Transaktionen zu ermitteln, der topologisch gültig bleibt, wenn er in einen Block aufgenommen wird. Er fand außerdem eine C++-Implementierung mehrerer Algorithmen für ähnliche Probleme, die “in der Praxis noch schneller sein sollen”.
Bisherige Arbeiten am Cluster-Mempool zielten darauf ab, einen schnellen und unkomplizierten Vergleich verschiedener Linearisierungen zu ermöglichen, sodass die beste ausgewählt werden kann. Dies würde es erlauben, einen schnellen Algorithmus zur sofortigen Cluster-Linearisierung einzusetzen, während ein langsamerer, aber optimierter Algorithmus auf verfügbaren CPU-Zyklen im Hintergrund läuft. Sollte jedoch der Algorithmus von 1989 zur Lösung des Maximum-Ratio-Closure-Problems oder ein anderer Algorithmus für dieses Problem ausreichend schnell arbeiten, könnte er fortlaufend eingesetzt werden – selbst wenn er nur moderat schnell ist, ließe sich sein Einsatz als Hintergrundalgorithmus rechtfertigen.
Pieter Wuille antwortete mit Begeisterung und mehreren Nachfolgefragen. Er beschrieb darüber hinaus einen neuen Cluster-Linearisierungsalgorithmus, den die Cluster-Mempool-Arbeitsgruppe auf Grundlage einer Diskussion von Bitcoin Research Week mit Dongning Guo und Aviv Zohar entwickelt hat. Dieser Ansatz transformiert das ursprüngliche Problem in eine Variante, die mittels linear programming gelöst werden kann, und scheint schnell, unkompliziert implementierbar und in der Lage zu sein, eine optimale Linearisierung zu erzeugen – sofern er tatsächlich terminiert. Allerdings bedarf es noch eines Beweises, dass er in einer vernünftigen Zeit terminiert.
Obgleich diese Forschung nicht direkt mit Bitcoin in Zusammenhang steht, fanden wir Richters Beschreibung interessant, in der er erläutert, wie er den Forschungsbericht von 1989 unter Zuhilfenahme des DeepSeek-Reasoning-LLM gefunden hat.
Zum Zeitpunkt des Schreibens war die Diskussion noch im Gange und weitere Forschungsberichte zu diesem Themengebiet wurden untersucht. Richter fasste zusammen: “Es scheint, dass unser Problem – oder vielmehr seine verallgemeinerte Lösung, die als source-sink-monotone parametrizierte Min-Cut bezeichnet wird – Anwendungen in Bereichen finden könnte, die als Polygon-Aggregation für die Kartenvereinfachung und andere Themen in der Computer-Vision bekannt sind.”
-
● Erlay-Update: Sergi Delgado veröffentlichte mehrere Beiträge auf Delving Bitcoin über seine Arbeit der letzten Jahre, bei der er Erlay für Bitcoin Core implementierte. Er beginnt mit einer Übersicht darüber, wie die bestehende Transaktions-Relay-Funktion (auch Fanout genannt) funktioniert und wie Erlay diese ändern will. Er bemerkt, dass ein gewisser Anteil an Fanout auch in einem Netzwerk, in dem jeder Knoten Erlay unterstützt, bestehen bleiben wird, da “Fanout effizienter und erheblich schneller ist als der Synchronisierung, vorausgesetzt, der empfangende Knoten kennt die angekündigte Transaktion nicht”.
Die Verwendung einer Mischung aus Fanout und Synchronisierung erfordert die Entscheidung, wann jede Methode verwendet werden soll und mit welchen Peers, sodass sich seine Forschung auf die optimale Auswahl konzentriert:
-
● Filtern basierend auf Transaktionswissen untersucht, ob ein Knoten einen Peer in seine Pläne zur Weiterleitung einer Transaktion einbeziehen sollte, auch wenn er weiß, dass der Peer die Transaktion bereits besitzt. Beispielsweise hat unser Knoten zehn Peers; drei dieser Peers haben bereits eine Transaktion an uns angekündigt. Wenn wir drei Peers zufällig auswählen möchten, um diese Transaktion weiter zu verbreiten, sollten wir aus allen zehn Peers oder nur den sieben auswählen, die uns die Transaktion noch nicht angekündigt haben? Überraschenderweise zeigen Simulationsergebnisse, dass “es keinen signifikanten Unterschied zwischen den Optionen gibt”. Delgado untersucht dieses überraschende Ergebnis und kommt zu dem Schluss, dass alle Peers berücksichtigt werden sollten (d. h. es sollte keine Filterung erfolgen).
-
● Wann Fanout-Kandidaten-Peers auswählen untersucht, wann ein Knoten entscheiden sollte, welche Peers eine Fanout-Transaktion erhalten (während der Rest über Erlay-Synchronisierung erfolgt). Zwei Zeitpunkte werden betrachtet: kurz nachdem ein Knoten eine neue Transaktion validiert und in die Warteschlange zur Weiterleitung gestellt hat, sowie wenn es Zeit ist, diese Transaktion zu verbreiten (Knoten leiten Transaktionen nicht sofort weiter, sondern warten eine kleine, zufällige Zeit, um es schwieriger zu machen, die Netzwerktopologie zu ermitteln und zu erraten, welcher Knoten die Transaktion ursprünglich gesendet hat – was schlecht für die Privatsphäre wäre). Auch hier zeigen Simulationsergebnisse, dass “es keine bedeutenden Unterschiede gibt”, wobei “die Ergebnisse variieren können […] in Netzwerken mit partieller [Erlay]-Unterstützung”.
-
● Wie viele Peers sollten eine Fanout erhalten untersucht die Fanout-Rate. Eine höhere Rate beschleunigt die Transaktionsverbreitung, reduziert jedoch die Bandbreiteneinsparungen. Neben dem Testen der Fanout-Rate untersuchte Delgado auch eine Erhöhung der Anzahl der ausgehenden Peers, da dies eines der Ziele der Erlay-Adoption ist. Die Simulation zeigt, dass der aktuelle Erlay-Ansatz die Bandbreite um etwa 35% reduziert, wenn die aktuellen Grenzwerte für ausgehende Peers (8 Peers) verwendet werden, und um 45%, wenn 12 ausgehende Peers genutzt werden. Allerdings steigt die Transaktionsverzögerung um etwa 240%. Viele weitere Kompromisse werden im Beitrag graphisch dargestellt. Zusätzlich bemerkt Delgado, dass die Ergebnisse nicht nur bei der Auswahl aktueller Parameter helfen, sondern auch bei der Bewertung alternativer Fanout-Algorithmen, die möglicherweise bessere Kompromisse bieten.
-
● Definition der Fanout-Rate basierend auf dem Empfang einer Transaktion untersucht, ob die Fanout-Rate angepasst werden sollte, je nachdem, ob eine Transaktion zuerst über Fanout oder durch Synchronisierung empfangen wurde. Weiterhin wird erörtert, welche angepasste Rate verwendet werden sollte, falls eine Anpassung erfolgen soll. Die Idee dahinter ist, dass Fanout schneller und effizienter ist, wenn eine neue Transaktion beginnt, durch das Netzwerk geleitet zu werden – jedoch führt dies zu unnötigem Bandbreitenverbrauch, nachdem die Transaktion bereits den Großteil der Knoten erreicht hat. Es gibt keine Möglichkeit für einen Knoten, direkt zu bestimmen, wie viele andere Knoten die Transaktion bereits gesehen haben. Ist es jedoch wahrscheinlich, dass eine Transaktion sich noch im frühen Stadium ihrer Verbreitung befindet, wenn der Peer, der sie zuerst gesendet hat, Fanout anstelle des Wartens auf die nächste geplante Synchronisierung verwendet hat, können diese Daten genutzt werden, um die eigene Fanout-Rate moderat zu erhöhen und die Verbreitung zu beschleunigen. Delgado simulierte diese Idee und fand ein modifiziertes Fanout-Verhältnis, das die Verbreitungszeit um 18% reduziert – bei nur einer 6,5%igen Erhöhung der Bandbreite im Vergleich zum Vergleichsergebnis, das die gleiche Fanout-Rate für alle Transaktionen verwendet.
-
-
● Kompromisse in LN-Ephemeral-Anker-Skripten: Bastien Teinturier postete auf Delving Bitcoin, um Meinungen zu den zu verwendenden Ephemeral-Anker- Skripten als Ersatz für bestehende Anker-Ausgaben in TRUC-basierten LN-Commitment-Transaktionen einzuholen. Das verwendete Skript bestimmt, wer die Commitment-Transaktion CPFP-Gebühren erhöhen kann (und unter welchen Bedingungen dies erfolgen kann). Er präsentierte dazu vier Optionen:
-
● Verwenden eines Pay-to-Anker-(P2A)-Skripts: Dieses Skript hat eine minimale On-Chain-Größe, führt jedoch dazu, dass der gesamte geschnürte HTLC- Wert aller Wahrscheinlichkeit nach an die Miner geht – wie es derzeit auch der Fall ist.
-
● Verwenden eines einzelteilnehmer-schlüsselbasierten Ankers: Dadurch könnte ein Überschuss an geschnürtem HTLC-Wert von einem Teilnehmer beansprucht werden, der sich freiwillig dazu bereit erklärt, einige Dutzend Blöcke zu warten, bevor er das aus dem Kanal abgeschlossene Geld ausgeben kann. Jeder, der einen Kanal zwangsweise schließen will, muss ohnehin warten. Allerdings kann keine der beiden Parteien die Zahlung der Gebühr an Dritte delegieren, ohne dass diese Gefahr laufen, alle Kanalfonds abzugreifen. Sollten sowohl Sie als auch Ihr Kontrahent um den Überschusswert konkurrieren, geht dieser höchstwahrscheinlich an die Miner.
-
● Verwenden eines gemeinsamen Schlüssel-Ankers: Dieser Ansatz ermöglicht ebenfalls die Rückgewinnung von überschüssigem, geschnürtem HTLC-Wert und erlaubt eine Delegation. Allerdings ist auch hier möglich, dass jeder, der die Delegation erhält, mit Ihnen und Ihrem Kontrahenten um den Überschusswert konkurriert – was im Falle eines Wettbewerbs dazu führt, dass der gesamte Überschusswert an die Miner geht.
-
● Verwenden eines dualen Schlüssel-Ankers: Dadurch kann jeder Teilnehmer den überschüssigen, geschnürten HTLC-Wert beanspruchen, ohne auf zusätzliche Blöcke warten zu müssen. Jedoch erlaubt diese Variante keine Delegation, sodass die beiden Parteien eines Kanals weiterhin direkt miteinander konkurrieren.
In Antworten auf den Beitrag bemerkte Gregory Sanders noted, dass die unterschiedlichen Ansätze zu verschiedenen Zeitpunkten zum Einsatz kommen könnten. Beispielsweise könnte P2A dann verwendet werden, wenn es keine geschnürten HTLCs gibt, während zu anderen Zeiten einer der schlüsselbasierten Anker sinnvoller ist. Ist der geschnürte Wert oberhalb der Staub-Schwelle, könnte dieser der LN-Commitment-Transaktion anstelle einer Anker-Ausgabe hinzugefügt werden. Zusätzlich warnte er davor, dass es zu “neuen Seltsamkeiten” kommen könnte, wenn ein Kontrahent versucht, den geschnürten Betrag zu erhöhen, um ihn selbst zu beanspruchen. David Harding baute zu diesem Thema in einem späteren Beitrag weiter aus.
Antoine Riard warnte vor der Verwendung von P2A, da dies das Risiko birgt, dass Miner zu Transaktions-Pinning animiert werden (siehe Newsletter #339).
Die Diskussion war zum Zeitpunkt des Schreibens noch im Gange.
-
-
● Emulieren von OP_RAND: Oleksandr Kurbatov postete auf Delving Bitcoin ein interaktives Protokoll, das es zwei Parteien ermöglicht, einen Vertrag abzuschließen, bei dem die Auszahlung auf eine Weise erfolgt, die für beide unvorhersehbar ist – funktional äquivalent zu einem Zufallsprinzip. Frühere Arbeiten zu wahrscheinlichen Zahlungen in Bitcoin (siehe dryja pp) haben bereits fortgeschrittene Skripte eingesetzt; im Unterschied dazu verwendet Kurbatovs Ansatz speziell konstruierte öffentliche Schlüssel, die es dem Gewinner erlauben, die vertraglich festgelegten Mittel auszugeben. Dieser Ansatz bietet zudem einen höheren Grad an Privatsphäre und könnte möglicherweise mehr Flexibilität ermöglichen.
Optech konnte das Protokoll nicht vollständig analysieren, stellte jedoch keine offensichtlichen Probleme fest. Wir hoffen auf weitere Diskussionen zu dieser Idee – wahrscheinliche Zahlungen haben vielfältige Anwendungen, unter anderem auch, um es Nutzern zu ermöglichen, Beträge on-chain zu senden, die ansonsten unwirtschaftlich wären, wie beispielsweise für getrimmte HTLCs.
-
● Diskussion über die Senkung der Mindest-Transaktions-Relay-Gebühr: Greg Tonoski postete auf der Bitcoin-Dev-Mailingliste über die Senkung der Standard-Mindest-Transaktions-Relay-Gebühr, ein Thema, das seit 2018 wiederholt diskutiert wurde (und von Optech zusammengefasst wurde) – zuletzt im Jahr 2022 (vgl. Newsletter #212). Bemerkenswert ist, dass eine kürzlich aufgedeckte Schwachstelle (siehe Newsletter #324) ein potenzielles Problem offenlegte, das Nutzer und Miner betreffen könnte, die in der Vergangenheit diese Einstellung gesenkt haben. Optech wird Updates bereitstellen, wenn es zu signifikanter weiterer Diskussion kommt.
Konsensänderungen
Ein monatlicher Abschnitt, der Vorschläge und Diskussionen zu Änderungen der Bitcoin-Konsensregeln zusammenfasst.
-
● Aktualisierungen des Cleanup-Soft-Fork-Vorschlags: Antoine Poinsot veröffentlichte mehrere Beiträge im Delving Bitcoin-Thread zum Konsens-Cleanup-Soft-Fork und schlug Parameteränderungen vor:
- ● Einführung einer Legacy-Eingabe-Sigops-Begrenzung:
In einem privaten Thread haben Poinsot und mehrere andere Mitwirkende versucht,
einen Block für Regtest zu erstellen, der die längste mögliche Zeit für die Validierung benötigt,
indem sie bekannte Probleme bei der Validierung von Legacy- (Vor-SegWit-) Transaktionen ausnutzen.
Nach Recherchen fand er heraus, dass er den “schlechtesten Block” anpassen konnte, um ihn unter den
ursprünglich vorgeschlagenen Maßnahmen von 2019 gültig zu machen (siehe
Newsletter #36). Dies führte ihn dazu, eine andere Maßnahme vorzuschlagen:
die Begrenzung der maximalen Anzahl von Signaturoperationen (Sigops) in Legacy-Transaktionen
auf 2.500. Jede Ausführung von
OP_CHECKSIGzählt als eine Sigop und jede Ausführung vonOP_CHECKMULTISIGkann bis zu 20 Sigops zählen (je nach Anzahl der verwendeten öffentlichen Schlüssel). Seine Analyse zeigt, dass dies die Worst-Case-Validierungszeit um 97,5% reduzieren wird.
Wie bei jeder Änderung dieser Art besteht das Risiko einer unbeabsichtigten Beschlagnahme aufgrund der neuen Regel, die zuvor unterzeichnete Transaktionen ungültig macht. Wenn Sie jemanden kennen, der Legacy-Transaktionen mit mehr als 2.500 Einzelsig-Operationen oder mehr als 2.125 Schlüsseln für Multisig-Operationen benötigt1, informieren Sie bitte Poinsot oder andere Protokollentwickler.
- ● Verlängern der Timewarp-Gnadenfrist auf 2 Stunden: Zuvor sah der Cleanup-Vorschlag vor, dass der erste Block in einem neuen Schwierigkeitsintervall keinen Blockheader-Timestamp haben durfte, der mehr als 600 Sekunden vor dem Timestamp des vorherigen Blocks lag. Dies bedeutete, dass eine konstante Hashrate die Timewarp-Sicherheitslücke nicht ausnutzen konnte, um Blöcke schneller als im 10-Minuten-Takt zu erzeugen.
Poinsot akzeptiert jetzt die Verwendung einer Gnadenfrist von 7.200 Sekunden (2 Stunden), wie ursprünglich von Sjors Provoost vorgeschlagen, da dies viel weniger wahrscheinlich zu einem unbeabsichtigten Fehler eines Miners führen würde, der einen ungültigen Block produziert. Allerdings ermöglicht diese Regel einem sehr geduldigen Angreifer, der mehr als 50 % der Netzwerk-Hashrate kontrolliert, die Timewarp-Attacke zu nutzen, um die Schwierigkeit über einen Zeitraum von Monaten zu senken – selbst wenn die tatsächliche Hashrate konstant bleibt oder steigt. Dies wäre ein öffentlich sichtbarer Angriff, und das Netzwerk hätte Monate Zeit zum Reagieren.
In seinem Beitrag fasst Poinsot frühere Argumente zusammen (siehe Newsletter #335 für unsere deutlich kürzere Zusammenfassung) und kommt zu dem Schluss, dass “trotz der vergleichsweise schwachen Befürwortungsargumente für eine Verlängerung der Gnadenfrist die damit verbundenen Kosten es nicht verbieten, auf Nummer sicher zu gehen.”
In einem Thread, der sich der Diskussion über die Verlängerung der Gnadenfrist widmete, diskutierten die Entwickler Zawy und Pieter Wuille diskutierten, wie die 600-Sekunden-Gnadenfrist – die anscheinend eine allmählich abnehmende Schwierigkeit bis zum Mindestwert zulässt – tatsächlich ausreicht, um mehr als einen kleinen Schwierigkeitsabfall zu verhindern. Insbesondere untersuchten sie die Auswirkungen von Bitcoins Off-by-One-Schwierigkeitsanpassungsfehler sowie die Asymmetrie der erlang-Verteilung auf die genaue Neuausrichtung der Schwierigkeit. Zawy fasste seine Argumentation wie folgt zusammen: “Es geht nicht darum, dass eine Anpassung sowohl für Erlang als auch für ‘2015-Loch’ nicht nötig wäre, sondern darum, dass 600 Sekunden vor dem vorherigen Block nicht als 600-Sekunden-Fehler zu werten sind, sondern als ein Fehler von 1200 Sekunden – weil wir tatsächlich einen Timestamp 600 Sekunden nach dem vorherigen erwartet hatten.”
- ● Lösung für duplizierte Transaktionen: Nach einer Anfrage nach Feedback von Minern (siehe Newsletter #332) bezüglich möglicher negativer Auswirkungen von Konsenslösungen auf das Problem der duplizierten Transaktionen wählte Poinsot eine spezifische Lösung, die in den Cleanup-Vorschlag aufgenommen werden soll: Die Höhe des vorherigen Blocks muss in jedem Time-Lock-Feld der Coinbase-Transaktion enthalten sein. Dieser Vorschlag hat zwei Vorteile: Er ermöglicht es, die festgelegte Blockhöhe aus einem Block zu extrahieren, ohne das Script parsen zu müssen, und er ermöglicht es, einen kompakten, SHA256-basierten Nachweis der Blockhöhe zu erstellen (im Worst-Case etwa 700 Bytes – viel weniger als der im Worst-Case benötigte 1-MB-Nachweis ohne ein fortschrittliches Nachweissystem).
Diese Änderung wird keine Auswirkungen auf normale Nutzer haben, aber sie wird letztlich Miner dazu zwingen, ihre Software zur Erstellung von Coinbase-Transaktionen zu aktualisieren. Sollten Miner Bedenken bezüglich dieses Vorschlags haben, wenden Sie sich bitte an Poinsot oder einen anderen Protokollentwickler.
Poinsot veröffentlichte außerdem eine hochrangige Aktualisierung über seine Arbeit und den aktuellen Stand des Vorschlags auf der Bitcoin-Dev-Mailingliste.
- ● Einführung einer Legacy-Eingabe-Sigops-Begrenzung:
In einem privaten Thread haben Poinsot und mehrere andere Mitwirkende versucht,
einen Block für Regtest zu erstellen, der die längste mögliche Zeit für die Validierung benötigt,
indem sie bekannte Probleme bei der Validierung von Legacy- (Vor-SegWit-) Transaktionen ausnutzen.
Nach Recherchen fand er heraus, dass er den “schlechtesten Block” anpassen konnte, um ihn unter den
ursprünglich vorgeschlagenen Maßnahmen von 2019 gültig zu machen (siehe
Newsletter #36). Dies führte ihn dazu, eine andere Maßnahme vorzuschlagen:
die Begrenzung der maximalen Anzahl von Signaturoperationen (Sigops) in Legacy-Transaktionen
auf 2.500. Jede Ausführung von
-
● Anfrage für ein Covenant-Design zur Unterstützung von Braidpool: Bob McElrath postete auf Delving Bitcoin und bat Entwickler, die an Covenant-Designs arbeiten, ihre bevorzugten oder neue Vorschläge in Betracht zu ziehen, um zu untersuchen, wie sie bei der Errichtung eines effizienten, dezentralen Minenpools helfen können. Das aktuelle Prototyp-Design für Braidpool verwendet eine Föderation von Unterzeichnern, bei der die Unterzeichner Schwellenwert-Unterschriften in Abhängigkeit von ihrem Anteil an der Hashleistung im Pool erhalten. Dies ermöglicht es einem Mehrheitsminer (bzw. einer Kollusion mehrerer Miner, die zusammen die Mehrheit bilden), Auszahlungen von kleineren Minern zu stehlen. McElrath bevorzugt die Verwendung eines Covenants, das sicherstellt, dass jeder Miner in der Lage ist, Mittel aus dem Pool anteilig zu seinen Beiträgen abzuheben. In seinem Beitrag legt er eine konkrete Liste von Anforderungen vor und begrüßt zudem einen Beweis der Unmöglichkeit.
Zum Zeitpunkt des Schreibens gab es noch keine Antworten.
-
● Deterministische Transaktionselektion aus einem festgeschriebenen Mem-Pool: Ein Thread aus April 2024 erhielt in diesem Monat erneute Aufmerksamkeit. Zuvor hatte Bob McElrath in einem Beitrag die Idee geäußert, dass Miner sich dazu verpflichten, ihre Transaktionen in den Mem-Pool aufzunehmen, und anschließend nur diejenigen Transaktionen in ihre Blöcke übernehmen, die anhand dieser Festlegungen deterministisch ausgewählt wurden. Er sieht zwei Anwendungsmöglichkeiten:
-
Globale Anwendung für alle Miner: Dies würde das “Risiko und die Haftung bei der Transaktionselektion” in einer Welt beseitigen, in der Miner häufig große Unternehmensstrukturen sind, die sich an geltende Gesetze, Vorschriften und die Empfehlungen von Risikomanagern halten müssen.
-
Lokale Anwendung für einen einzelnen Pool: Dieser Ansatz bietet nahezu die gleichen Vorteile wie ein global deterministischer Algorithmus, erfordert jedoch keine Konsensänderungen. Außerdem kann er die Bandbreite zwischen den Peers in einem dezentralen Minenpool wie Braidpool erheblich einsparen, da der Algorithmus genau festlegt, welche Transaktionen ein Kandidatenblock enthalten muss – sodass bei der Erzeugung eines jeden Shares keine Transaktionsdaten explizit an die Pool-Peers übermittelt werden müssen.
Anthony Towns beschrieb mehrere potenzielle Probleme einer globalen Konsensänderung: Jede Veränderung der Transaktionselektion würde zwangsläufig eine Konsensänderung (möglicherweise in Form eines Hard Forks) nach sich ziehen, und jeder, der eine nicht-standardmäßige Transaktion erstellt, wäre nicht in der Lage, diese abgebaut zu bekommen – selbst mit der Zusammenarbeit eines Miners. Kürzliche Richtlinienänderungen der letzten Jahre, die eine Konsensänderung erfordert hätten, umfassen TRUC, aktualisierte RBF-Richtlinien und ephemeral anchors. Towns verlinkte zu einem bekannten Fall, in dem Millionen von Dollar an Wert versehentlich in ein nicht-standardmäßiges Skript gesteckt wurden, welches ein kooperativer Miner wieder freigeben konnte.
Die verbleibende Diskussion richtete sich auf den lokalen Ansatz, wie er für Braidpool konzipiert wurde. Es gab keinerlei Einwände, und zusätzliche Gespräche über einen Schwierigkeitsanpassungsalgorithmus (siehe nächster Punkt in diesem Abschnitt) verdeutlichten, wie vorteilhaft dieser Ansatz insbesondere für einen Pool sein könnte, der Blöcke in einer deutlich höheren Frequenz als Bitcoin erzeugt – da die deterministische Transaktionselektion dadurch Bandbreite, Latenz und Validierungskosten signifikant reduziert.
-
-
● Schneller Schwierigkeitsanpassungsalgorithmus für eine DAG-Blockchain: Der Entwickler Zawy postete auf Delving Bitcoin über einen Mining-Schwierigkeitsanpassungsalgorithmus (DAA) für eine DAG-Blockchain. Der Algorithmus wurde entworfen für den Einsatz im Peer-Konsens von Braidpool (nicht für den globalen Bitcoin-Konsens), wobei die Diskussion wiederholt globale Konsensaspekte berührte.
In Bitcoins Blockchain verweist jeder Block exakt auf einen einzigen Eltern-Block; mehrere Kind-Blöcke können denselben Eltern-Block referenzieren, jedoch wird von einem Knoten nur einer dieser Blöcke auf der besten Blockchain als gültig betrachtet. In einer DAG-Blockchain kann hingegen ein Block einem oder mehreren Eltern-Blöcken zugeordnet werden und null oder mehr Kinder haben; die sogenannte “DAG-beste Blockchain” kann mehrere Blöcke derselben Generation als gültig einstufen.
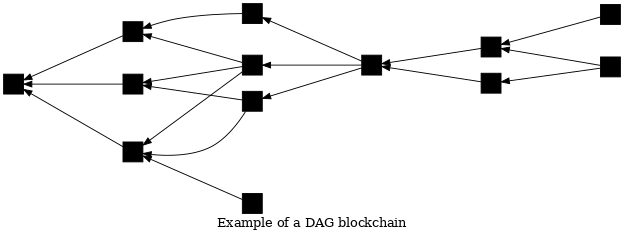
Der vorgeschlagene DAA zielt darauf ab, den Durchschnitt der Eltern-Blöcke in den letzten 100 gültigen Blöcken zu kontrollieren. Steigt dieser Durchschnitt, erhöht der Algorithmus die Schwierigkeit; sinkt er, verringert sich die Schwierigkeit. Laut Zawy führt ein Durchschnitt von zwei Eltern-Blöcken zum schnellsten Konsens. Anders als Bitcoins DAA benötigt der vorgeschlagene Algorithmus keine Zeiterfassung; allerdings erfordert er, dass Peers Blöcke ignorieren, die wesentlich später als andere Blöcke derselben Generation eintreffen. Da sich über verspätete Blöcke kein Konsens erzielen lässt, werden letztlich DAGs mit mehr Proof-of-Work (PoW) gegenüber solchen mit weniger PoW bevorzugt. Der Entwickler des DAA, Bob McElrath, analysierte das Problem sowie eine mögliche Gegenmaßnahme.
Pieter Wuille kommentierte, dass der Vorschlag einer 2012-Idee von Andrew Miller ähnelt; Zawy stimmte zu und McElrath wird seinen Artikel mit einer entsprechenden Zitation aktualisieren. Sjors Provoost diskutierte die Komplexität der Handhabung von DAG-Ketten in der aktuellen Architektur von Bitcoin Core, stellte jedoch fest, dass dies mit libbitcoin und unter Zuhilfenahme von utreexo möglicherweise einfacher zu bewältigen sei. Zawy simulierte umfassend das Protokoll und gab an, dass er an weiteren Simulationen für Varianten des Protokolls arbeite, um die optimale Mischung an Trade-offs zu ermitteln.
Der letzte Beitrag zum Diskussionsthread wurde etwa einen Monat vor dieser Zusammenfassung verfasst, aber es wird erwartet, dass Zawy und die Braidpool-Entwickler das Protokoll weiterhin analysieren und implementieren.
Releases und Release-Kandidaten
Neue Veröffentlichungen und Release-Kandidaten für beliebte Bitcoin-Infrastrukturprojekte. Bitte ziehen Sie in Erwägung, auf neue Veröffentlichungen zu aktualisieren oder Release-Kandidaten zu testen.
-
● BDK Wallet 1.1.0 ist eine Veröffentlichung dieser Bibliothek für den Bau von Bitcoin-fähigen Anwendungen. Sie verwendet standardmäßig Transaktionsversion 2 (was die Privatsphäre verbessert, indem BDK-Transaktionen mit anderen Wallets, die aufgrund ihrer Unterstützung für relative Locktimes v2-Transaktionen verwenden müssen, vermischt werden können – siehe Newsletter #337). Zudem fügt sie Unterstützung für kompakte Block-Filter hinzu (siehe Newsletter #339) sowie “verschiedene Bugfixes und Verbesserungen”.
-
● LND v0.18.5-beta.rc1 ist ein Release-Kandidat für eine Minor-Version dieser beliebten LN-Node-Implementierung.
Wichtige Code- und Dokumentationsänderungen
Die jüngsten, herausragenden Änderungen in Bitcoin Core, Core Lightning, Eclair, LDK, LND, libsecp256k1, Hardware Wallet Interface (HWI), Rust Bitcoin, BTCPay Server, BDK, Bitcoin Improvement Proposals (BIPs), Lightning BOLTs, Lightning BLIPs, Bitcoin Inquisition und BINANAs
-
● Bitcoin Core #21590 implementiert einen safegcd-basierten modularen Inversions-Algorithmus für MuHash3072 (siehe Newsletter #131 und #136), basierend auf der Implementierung von libsecp256k1, während er Unterstützung für sowohl 32-Bit- als auch 64-Bit-Architekturen hinzufügt und sich auf den spezifischen Modulus spezialisiert. Benchmark-Ergebnisse zeigen eine ungefähre 100-fache Leistungsverbesserung auf x86_64, wodurch die MuHash-Berechnung von 5,8 ms auf 57 μs reduziert wird – und somit der Weg für eine effizientere Zustandsvalidierung geebnet wird.
-
● Eclair #2983 modifiziert die Synchronisation der Routing-Tabelle bei einer erneuten Verbindung, sodass nur Kanalankündigungen mit den Top-Peers des Knotens (bestimmt durch die gemeinsame Kanalkapazität) synchronisiert werden, um den Netzwerkoverhead zu reduzieren. Darüber hinaus wurde das Standardverhalten der Synchronisations-Whitelist (siehe Newsletter #62) aktualisiert: Um die Synchronisation mit Peers, die nicht auf der Whitelist stehen, zu deaktivieren, müssen Benutzer nun
router.sync.peer-limitauf 0 setzen (der Standardwert ist 5). -
● Eclair #2968 fügt Unterstützung für Splicing auf öffentlichen Kanälen hinzu. Sobald die Splice-Transaktion bestätigt und auf beiden Seiten gesperrt ist, tauschen die Knoten Announcements-Signaturen aus und senden anschließend eine
channel_announcement-Meldung an das Netzwerk. Kürzlich wurde in Eclair die Nachverfolgung von Splicing-Vorgängen Dritter als Voraussetzung dafür integriert (siehe Newsletter #337). Dieses PR verbietet außerdem die Verwendung vonshort_channel_idfür das Routing auf privaten Kanälen und priorisiert stattdessenscid_alias, um sicherzustellen, dass das Channel-UTXO nicht offengelegt wird. -
● LDK #3556 verbessert die Behandlung von HTLCs, indem es HTLCs proaktiv rückabwickelt, wenn sie dem Ablauf zu nahe kommen – und dies, noch bevor ein upstream On-Chain-Claim zur Bestätigung vorliegt. Zuvor verzögerte ein Knoten das Rückabwickeln der HTLCs um zusätzliche drei Blöcke, um dem Claim genügend Zeit zur Bestätigung zu geben. Diese Verzögerung brachte jedoch das Risiko mit sich, dass der Kanal zwangsweise geschlossen wird. Zudem wurde das Feld
historical_inbound_htlc_fulfillsentfernt, um den Kanalstatus aufzuräumen, und ein neues FeldSentHTLCIdeingeführt, um Verwirrung durch doppelte HTLC-IDs bei eingehenden Kanälen zu vermeiden. -
● LND #9456 fügt den Endpunkten
SendToRoute,SendToRouteSync,SendPaymentundSendPaymentSyncDeprecation-Warnungen hinzu, um deren Abschaffung in der übernächsten Version (0.21) vorzubereiten. Benutzer werden aufgefordert, auf die neuen v2-MethodenSendToRouteV2,SendPaymentV2undTrackPaymentV2umzusteigen.
Footnotes
-
Bei P2SH und der vorgeschlagenen Zählweise der Input-Sigops wird ein
OP_CHECKMULTISIGmit mehr als 16 öffentlichen Schlüsseln als 20 Sigops gezählt, sodass jemand, derOP_CHECKMULTISIG125 Mal mit jeweils 17 Schlüsseln verwendet, insgesamt als 2.500 Sigops gewertet wird. ↩