
/ home / newsletters /
Bitcoin Optech Newsletter #274
This week’s newsletter describes the replacement cycling attack against
HTLCs used in LN and other systems, examines the mitigations deployed
for the attack, and summarizes several proposals for additional
mitigations. Also described are a notable bug affecting a Bitcoin Core
RPC, research into covenants with minimal changes to Bitcoin Script, and
a proposed BIP for an OP_CAT opcode. Also included is our regular
monthly section with summaries of popular questions and answers from the
Bitcoin Stack Exchange.
News
-
● Replacement cycling vulnerability against HTLCs: As briefly mentioned in last week’s newsletter, Antoine Riard posted to the Bitcoin-Dev and Lightning-Dev mailing lists about a responsibly disclosed vulnerability affecting all LN implementations. Since the disclosure, implementations have been updated to include mitigations for the attack and we strongly recommend upgrading to the latest version of your preferred LN software. Only nodes being used to forward payments are affected; users who only use their channels to initiate and receive payments are not affected.
We’ve organized our description of this story into three separate news items: a description of the vulnerability (this item), a description of the mitigations deployed so far by various LN implementations, and a summary of additional mitigations and solutions proposed on the mailing list.
As background, it’s possible to use transaction replacement to remove one or more inputs of a multi-input transaction from node mempools. To take a simple example, one that differs slightly from Riard’s original description, Mallory broadcasts a transaction with two inputs, which spend outputs A and B. She then replaces that transaction with an alternative single-input version that only spends output B. After that replacement, input A—and any data included in it—has been removed from any node mempools that processed the replacement.
Although it’s not safe for a regular wallet to do that1, it’s a behavior that Mallory can exploit if she wants to remove an input from node mempools.
In particular, if Mallory shares control over an output with Bob, she can wait for him to spend the output, replace his spend with a spend of her own that contains an additional input, and then replace her spend with a transaction that no longer spends their shared output. This is a replacement cycle. Miners will still collect transaction fees from Mallory but there’s a high probability that neither Bob’s nor Mallory’s spends of the output will get confirmed anywhere near the time that Bob broadcasts his spend.
That’s important in the case of LN and several other protocols because certain transactions need to occur within certain time windows to ensure that users who forward payments don’t lose money. For example, Mallory uses one of her nodes (which we’ll call MalloryA) to forward a payment to Bob and Bob forwards that payment to another of Mallory’s nodes (MalloryB). MalloryB is supposed to either give Bob a preimage that allows him to accept the forwarded payment from MalloryA, or MalloryB is supposed to cancel (revoke) the forwarded payment she received from Bob before a certain time. Instead, MalloryB does nothing by the designated time and Bob is forced to close the channel and broadcast a transaction that spends the forwarded payment back to himself. That spend should confirm promptly, allowing Bob to cancel (revoke) the spend he received from MalloryA, which returns everyone’s balance to the amounts they were before the attempt to forward the payment (with the exception of any transaction fees paid to close and settle the Bob-MalloryB channel).
Alternatively, when Bob closes the channel and attempts to spend the forwarded payment back to himself, MalloryB can replace his spend with a spend of her own containing the preimage. If that transaction confirmed promptly, Bob would learn the preimage and be able to claim the forwarded payment from MalloryA, making Bob happy.
However, if MalloryB replaces Bob’s spend with a spend of her own that contains the preimage, after which she quickly removes that input, then it’s unlikely that either Bob’s spend or MalloryB’s preimage will appear in the block chain. This prevents Bob from getting his money back from MalloryB. Without the preimage, the trustless LN protocol prevents Bob from being able to keep the forwarded payment from MalloryA, so he gives her a refund. At this point, MalloryB gets her spend containing the preimage confirmed, allowing her to claim the forwarded payment from Bob. That means, if an amount of x was forwarded, MalloryA pays zero, MalloryB receives x, and Bob loses x (not counting various fees).
For the attack to be profitable, MalloryB must share a channel with Bob—but MalloryA can be anywhere along the forwarding path to Bob. For example:
MalloryA -> X -> Y -> Z -> Bob -> MalloryBReplacement cycling has similar consequences for LN nodes to existing transaction pinning attacks. However, techniques such as v3 transaction relay that were designed to prevent pinning for LN and similar protocols do not prevent replacement cycling.
-
● Deployed mitigations in LN nodes for replacement cycling: as described by Antoine Riard, several mitigations have been deployed by LN implementations.
-
● Frequent rebroadcasting: after a relay node’s mempool has Bob’s spend replaced by Mallory’s spend, and then has Mallory’s input removed by Mallory’s second replacement, that relay node will immediately be willing to accept Bob’s spend again. All Bob needs to do is re-broadcast his spend, which costs him nothing beyond the transaction fee he was already willing to pay.
Before the private disclosure of replacement cycling, LN implementations only rebroadcast their transactions infrequently (once per block or less). There’s normally a privacy cost to broadcasting and rebroadcasting transactions—it might make it easier for third parties to associate Bob’s onchain LN activities with his IP address—although few public LN forwarding nodes currently try to hide this. Now Core Lightning, Eclair, LDK, and LND will all rebroadcast more frequently.
After each time Bob rebroadcasts, Mallory can use the same technique to replace his transaction again. However, the BIP125 replacement rules will require Mallory to pay additional transaction fees for each of her replacements, meaning each rebroadcast by Bob lowers the profitability to Mallory of a successful attack.
This suggests a rough formula for the maximum amount of an HTLC that a node should accept. If the cost the attacker will need to pay for each replacement cycle is x, the number of blocks the defender has is y, and the number of effective rebroadcasts the defender will make per average block is z, an HTLC is probably reasonably secure up to a value a bit below
x*y*z. -
● Longer CLTV expiry deltas: when Bob accepts an HTLC from MalloryA, he agrees to allow her to claim an onchain refund after a certain number of blocks (let’s say 200 blocks). When Bob offers an equivalent HTLC to MalloryB, she allows him to claim a refund after a smaller number of blocks (let’s say, 100 blocks). Those expiry conditions are written using the
OP_CHECKLOCKTIMEVERIFY(CLTV) opcode, so the delta between them is called the CLTV expiry delta.The longer a CLTV expiry delta is, the longer the originating spender of a payment will need to wait to recover their funds if the payment fails, so spenders prefer to route payments through channels with shorter deltas. However, it’s also the case that, the longer a delta is, the more time a forwarding node like Bob has to respond to problems like transaction pinning and mass channel closures. These competing interests have led to frequent tweaks of the default delta in LN software (see Newsletters #40, #95, #109, #112, #142, #248, and #255).
In the case of replacement cycling, a longer CLTV delta gives Bob more rounds of rebroadcasting, which raises the cost of the attack according to the rough formula mentioned in the rebroadcast mitigation description.
Additionally, each time Bob’s rebroadcast spend is in a miner’s mempool, there’s a chance that the miner will include it in a block template that gets mined, resulting in the attack failing. Mallory’s initial replacement with her preimage could also get mined before she has a chance to replace it further, again resulting in the attack failing. If each cycle results in those two transactions spending a certain amount of time in miner mempools, than each rebroadcast by Bob multiplies that time. The CLTV expiry delta further multiplies that time.
For example, even if those transactions only spend 1% of the time per block in the average miner’s mempool, there’s about a 50% chance that the attack will fail with a CLTV expiry delta of just 70 blocks. Using the current default CLTV expiry delta numbers for different LN implementations listed in Riard’s email, the following plot shows the probability that Mallory’s attack will fail (and she loses any money she spent on replacements) under the assumption that the expected HTLC spends are in miner mempools for either 0.1% of the time, 1% of the time, or 5% of the time. For reference, given a 600-second average time between blocks, those percentages correspond to just 0.6 seconds, 6 seconds, and 30 seconds out of every 10 minutes.
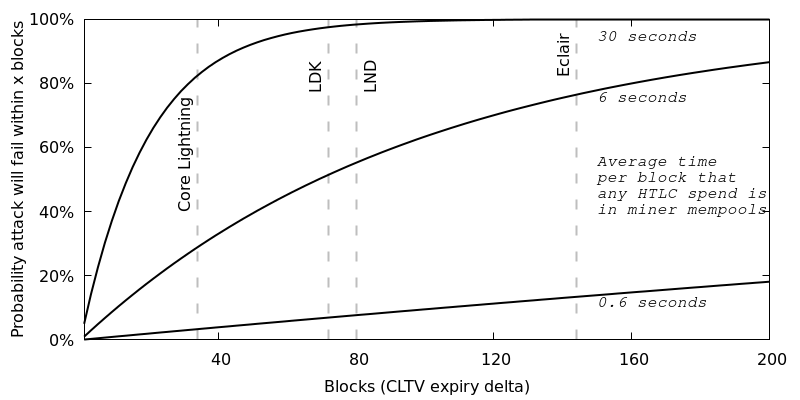
-
● Mempool scanning: HTLCs were designed to incentivize Mallory to get her preimage confirmed into the block chain before Bob can claim his refund. This is convenient for Bob: the block chain is widely available and limited in size, so Bob can easily find any preimage that affects him. If this system worked as intended, Bob could get all the information he needs to trustlessly operate on LN from the block chain.
Unfortunately, replacement cycling means Mallory may no longer be incentivized to confirm her transaction before Bob’s refund can be claimed. Yet, to initiate a replacement cycle, Mallory still needs to briefly disclose her preimage to miner mempools in order to replace Bob’s spend. If Bob runs a relaying full node, Mallory’s preimage transaction may propagate across the network to Bob’s node. If Bob then detects the preimage before he’s due to give MalloryA a refund, the attack is defeated and Mallory loses any money she spent on attempting it.
Mempool scanning isn’t perfect—there’s no guarantee that Mallory’s replacement transaction will propagate to Bob. However, the more times Bob rebroadcasts his transaction (see rebroadcast mitigation) and the more time Mallory needs to keep her preimage hidden from Bob (see CLTV expiry delta mitigation), the more likely it is that one of the preimage transactions will make it into Bob’s mempool in time for him to defeat the attack.
Eclair and LND currently implement mempool scanning when used as forwarding nodes.
-
● Discussion of mitigation effectiveness: Riard’s initial announcement said, “I believe replacement cycling attacks are still practical for advanced attackers.” Matt Corallo wrote, “the deployed mitigations are not expected to fix this issue; its arguable if they provide anything more than a PR statement.” Olaoluwa Osuntokun argued, “[in my opinion], this is a rather fragile attack, which requires: per-node setup, extremely precise timing and execution, non-confirming superposition of all transactions, and instant propagation across the entire network”.
We at Optech think it’s important to restate that this attack only affects forwarding nodes. A forwarding node is a Bitcoin hot wallet connected to an always-on internet service—a type of deployment that is perpetually one vulnerability away from having all of its funds stolen. Anyone evaluating the effect of replacement cycling on the risk profile of operating an LN forwarding node should consider it in the context of the risk that is already being tolerated. Of course, it’s worth searching for other ways to reduce that risk, as discussed in our next news item.
-
-
● Proposed additional mitigations for replacement cycling: as of this writing, there have been over 40 separate posts made to the Bitcoin-Dev and Lightning-Dev mailing lists in response to the disclosure of the replacement cycling attack. Suggested responses included the following:
-
● Incrementing fees towards scorched earth: Antoine Riard’s paper about the attack and mailing list posts by Ziggie and Matt Morehouse suggest that, instead of having the defender (e.g. Bob) just rebroadcast his refund spend, he starts broadcasting conflicting alternative spends that pay ever-increasing feerates as the deadline approaches with the upstream attacker (e.g. MalloryA).
The BIP125 rules require the downstream attacker (e.g. MalloryB) pay even higher fees for each of her replacements of Bob’s spend, meaning Bob can further reduce the profitability of the attack if Mallory is successful. Consider our rough
x*y*zformula described in the rebroadcasting mitigation section. If the cost of x is increased for some of the rebroadcasts, the overall cost to the attacker increases and the maximum safe value of an HTLC is higher.Riard argues in his paper that the costs may not be symmetric, particularly during periods where typical feerates are increasing and the attacker may be able to get some of their transactions evicted from miner mempools. On the mailing list, he also argues that an attacker can spread his attack across multiple victims using a form of payment batching, slightly increasing its efficacy.
Matt Corallo notes the major downside of this approach compared to just rebroadcasting: even if Bob defeats the attacker, Bob loses some of the HTLC value (or, potentially, all of it). Theoretically, an attacker won’t challenge a defender who they believe will follow a policy of mutually assured destruction, so Bob would never actually need to pay higher and higher feerates. Whether that would be true in practice on the Bitcoin network is unproven.
-
● Automatic retrying of past transactions: Corallo suggested that, “the only fix for this issue will be when miners keep a history of transactions they’ve seen and try them again after […] an attack like this.” Bastien Teinturier replied, “I agree with Matt though that more fundamental work most likely needs to happen at the bitcoin layer to allow L2 protocols to be more robust against that class of attacks.” Riard also said something similar, “a sustainable fix can [only] happen at the base-layer, e.g adding a memory-intensive history of all seen transactions”.
-
● Presigned fee bumps: Peter Todd argued that, “the correct way to do pre-signed transactions is to pre-sign enough different transactions to cover all reasonable needs for bumping fees. […] There is zero reason why the B->C transactions should be getting stuck.” (Emphasis in the original.)
That could work something like this: for the HTLC between Bob and MalloryB, Bob gives MalloryB ten different signatures for the same preimage spend at different feerates. Note that this doesn’t require that MalloryB disclose the preimage to Bob at signing time. At the same time, MalloryB gives Bob ten different signatures for the same refund spend at different feerates. This can be done before the refund can be broadcast. The feerates used might be (in sats/vbyte): 1, 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, which should cover anything for the foreseeable future.
If MalloryB’s preimage spend was presigned, the only replacement she could make would be to go from one feerate to a higher feerate. She couldn’t add new inputs to the preimage spend, and without that capability, she would be unable to initiate the replacement cycle.
-
● OP_EXPIRE: in a separate thread, but quoting from the replacement cycles thread, Peter Todd proposed several consensus changes to enable an
OP_EXPIREopcode that would make a transaction invalid for inclusion after a specified block height if the transaction’s script executesOP_EXPIRE. This can be used to make Mallory’s preimage condition of an HTLC only usable before Bob’s refund condition becomes spendable. This prevents Mallory from being able to replace Bob’s refund spend, making it impossible for Mallory to execute a replacement cycle attack.OP_EXPIREmay also address some transaction pinning attacks against HTLCs.The main downside of
OP_EXPIREis that it requires changes to consensus to enable and changes to relay and mempool policy to avoid certain problems, such as it being used to waste node bandwidth.A reply to the proposal suggested a weaker way to accomplish some of the same goals as
OP_EXPIREbut without any consensus or relay policy changes required. However, Peter Todd argued that it doesn’t prevent the replacement cycling attack.
Optech expects continued discussion about the subject and will summarize any notable developments in future newsletters.
-
-
● Bitcoin UTXO set summary hash replacement: Fabian Jahr posted to the Bitcoin-Dev mailing list to announce that a bug had been discovered in Bitcoin Core’s calculation of the hash of the current UTXO set. The hash did not commit to the height and coinbase information for each UTXO, information that is needed for enforcing the 100-block coinbase maturity rule and BIP68 relative timelocks. All of that information is still in the database of a node that’s been synced from scratch (all current Bitcoin Core nodes) and it’s still used for enforcement, so this bug does not affect any known released software. However, the experimental assumeUTXO feature planned for the next major version of Bitcoin Core will allow users to share their UTXO databases with each other. The incomplete commitment means that a modified database could have the same hash as a verified database, potentially opening a narrow window for an attack against assumeUTXO users.
If you’re aware of any software that uses the
hash_serialized_2field, please notify its authors about the problem and encourage them to read Jahr’s email about the changes being made for the next major version of Bitcoin Core to address the bug. -
● Research into generic covenants with minimal Script language changes: Rusty Russell posted to the Bitcoin-Dev mailing list a link to some research he has performed about using a few simple new opcodes to allow a script being executed in a transaction to inspect the output scripts being paid in that same transaction, a powerful form of introspection. The ability to perform introspection of output scripts (and the commitments they make) allows the implementation of covenants. Some of his findings that we thought were significant included:
-
● Simple: with three new opcodes, plus any one of several covenant opcodes previous proposed (like OP_TX), a single output script and its taproot commitment can be fully introspected. Each of the new opcodes is simple to understand and appear simple to implement.
-
● Fairly concise: Russell’s example uses about 30 vbytes to perform a reasonable introspection (the size of the script to be enforced would be in addition to those vbytes).
-
● OP_SUCCESS changes would be beneficial: the BIP342 specification of tapscript specifies several
OP_SUCCESSxopcodes that make any script including them always succeed, allowing future soft forks to attach conditions to the opcodes (making them behave like regular opcodes). However, that behavior makes it unsafe to use introspection with a covenant that allows including parts of an arbitrary script. For example, Alice might want to create a covenant that allows her to spend her funds to an arbitrary address if she first spends her funds in a vault notification transaction and waits for some number of blocks to allow a freeze transaction to block the spend. However, if the arbitrary address includes anOP_SUCCESSxopcode, anyone will be able to steal her money. Russell suggests two possible solutions to this problem is his research.
The research received some discussion and Russell indicated that he is working on a follow-up post related to introspection of output amounts.
-
-
● Proposed BIP for OP_CAT: Ethan Heilman posted to the Bitcoin-Dev mailing list a proposed BIP to add an OP_CAT opcode to tapscript. The opcode would take two elements at the top of the stack and concatenate them into a single element. He links to several descriptions of the capabilities that
OP_CATby itself would add to Script. His proposed reference implementation is only 13 lines of code (excluding whitespace).The proposal received a moderate amount of discussion, most of it focused on limits in tapscript that might affect the usefulness and worst-case costs of enabling
OP_CAT(and whether any of those limits should be changed).
Selected Q&A from Bitcoin Stack Exchange
Bitcoin Stack Exchange is one of the first places Optech contributors look for answers to their questions—or when we have a few spare moments to help curious or confused users. In this monthly feature, we highlight some of the top-voted questions and answers posted since our last update.
-
● How does the Branch and Bound coin selection algorithm work? Murch summarizes his research work on the Branch and Bound algorithm for coin selection that “searches for the least wasteful input set that produces a changeless transaction”.
-
● Why is each transaction broadcast twice in the Bitcoin network? Antoine Poinsot responds to an early mailing list post from Satoshi that noted “Each transaction has to be broadcast twice”. Poinsot clarified that while at that time a transaction was broadcast twice (once during transaction relay and once during block relay), the subsequent addition of BIP152 compact block relay means the transaction data only needs to be broadcast once to a peer.
-
● Why are OP_MUL and OP_DIV disabled in Bitcoin? Antoine Poinsot points out that the
OP_MULandOP_DIVopcodes were probably disabled, in addition to other opcodes, as a result of the “1 RETURN” and OP_LSHIFT crash bugs discovered in the weeks prior. -
● Why are hashSequence and hashPrevouts computed separately? Pieter Wuille explains that by splitting up to-be-signed transaction hash data into previous outputs and sequences, those hash values can be used once for the whole transaction involving all types of sighashes.
-
● Why does Miniscript add an extra size check for hash preimage comparisons? Antoine Poinsot notes that hash preimages are limited in size in miniscript to avoid non-standard Bitcoin transactions, avoid consensus-invalid cross-chain atomic swaps, and ensure that witness costs can be accurately calculated.
-
● How can the next block fee be less than the mempool purging fee rate? User Steven references mempool.space dashboards showing a default mempool purging 1.51sat/vb transactions while also indicating an estimated next block containing transactions with 1.49sat/vb. Glozow outlines the likely explanation as a full mempool resulting in the eviction of a transaction that bumped the node’s mempool min feerate (by
-incrementalRelayFee) but left some lower feerate transactions in the mempool that did not need to be evicted in order to stay within the maximum mempool size.She also mentions the asymmetry between ancestor scoring for block template selection and descendant scoring for mempool eviction as another possible explanation and links to a cluster mempool-related issue explaining the asymmetry and a potential new approach.
Releases and release candidates
New releases and release candidates for popular Bitcoin infrastructure projects. Please consider upgrading to new releases or helping to test release candidates.
-
● Bitcoin Core 25.1 is a maintenance release mainly containing bug fixes. It is the current recommended version of Bitcoin Core.
-
● Bitcoin Core 24.2 is a maintenance release mainly containing bug fixes. It is recommended for anyone still using 24.0 or 24.1 who is unable or unwilling to upgrade to 25.1 at this time.
-
● Bitcoin Core 26.0rc1 is a release candidate for the next major version of the predominant full node implementation. Verified test binaries have not yet been released as of this writing, although we expect them to be published at the preceding URL shortly after publication of the newsletter. Previous release candidates for major releases have had a testing guide on the Bitcoin Core developer wiki and a meeting of the Bitcoin Core PR Review Club dedicated to testing. We encourage interested readers to periodically check to see if those resources become available for the new release candidate.
Notable code and documentation changes
Due to the volume of news this week, and other constraints on our primary writer’s time, we were unable to review the past week’s code changes. We will include them as part of next week’s newsletter. We apologize for the delay.
Footnotes
-
The replacement cycle attack described here is based on a replacement transaction including fewer inputs than the original transaction it replaces. That’s a behavior wallet authors are typically warned to avoid. For example, the book Mastering Bitcoin, 3rd edition says:
Be very careful when creating more than one replacement of the same transaction. You must ensure that all versions of the transactions conflict with each other. If they aren’t all conflicts, it may be possible for multiple separate transactions to confirm, leading you to overpay the receivers. For example:
-
Transaction version 0 includes input A.
-
Transaction version 1 includes inputs A and B (e.g., you had to add input B to pay the extra fees)
-
Transaction version 2 includes inputs B and C (e.g., you had to add input C to pay the extra fees but C was large enough that you no longer need input A).
In the above scenario, any miner who saved version 0 of the transaction will be able to confirm both it and version 2 of the transaction. If both versions pay the same receivers, they’ll be paid twice (and the miner will receive transaction fees from two separate transactions).
A simple method to avoid this problem is to ensure the replacement transaction always includes all of the same inputs as the previous version of the transaction.
-