
用批量支付扩展比特币
本文介绍了高频支付用户如何利用批量添加这一扩容技术,在实际使用情形下,将交易手续费与区块空间占用减少约 75%。 截至 2021 年 1 月,已有多家主流比特币服务(主要是交易所)在使用批量添加,许多钱包(包括 Bitcoin Core)也将其作为内置功能提供,定制钱包或支付发送解决方案中实现这一功能也应当十分容易。不过需要注意的是,这项技术可能会在一段时间内导致收款人看到的行为与预期不符,并且会影响手续费提升(fee bump),同时也可能降低隐私性。
每位收款人的交易体积
如果使用 P2WPKH 输入和输出的一笔典型比特币交易包含来自付款方的 1 个输入(约 67 vbytes),以及 2 个输出(各约 31 vbytes,分别支付给收款人和找零支付给付款方),还需要 额外的 11 vbytes 用于交易头部字段(version、locktime 以及其他字段)。
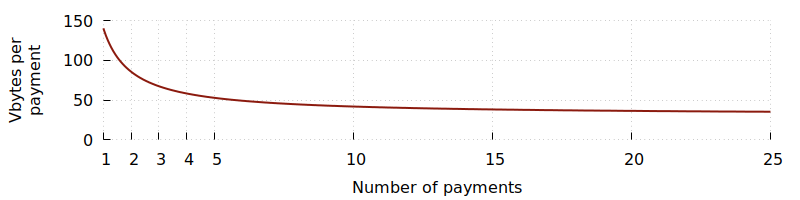
若添加 4 个收款人,每位收款人需额外增加 1 个 31 vbytes 的输出,交易的总体大小将变为 264 vbytes。之前的交易消耗全部 140 vbytes 来支付给 1 位收款人,而现在合并后的交易则只有约 53 vbytes 用于每位收款人,相比之下省下了大约 60% 的空间占用。
在此最佳情形之下继续推算可见,随着支付收款人数量的增多,每位收款人的平均 vbytes 数值会逐渐接近单个输出大小,其最高可带来的节省率略高于 75%。
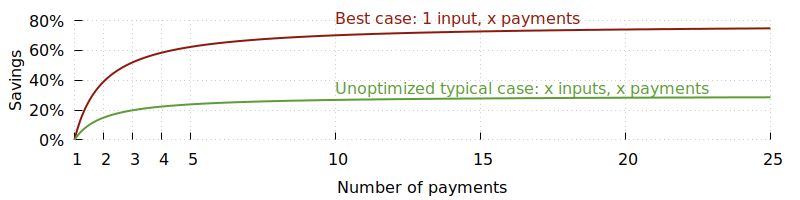
在现实情况下,随着交易金额的增大,往往需要更多的输入。这并不会削弱批量添加的实用性,但会在一定程度上降低它的效率。举例来说,一些服务的收款金额与其发送给客户的金额相近,那么平均而言,服务每新加 1 个输出就需要额外增加 1 个输入。这样其最高节省率约为 30%。
如果某项服务发现自己在大多数交易中都要使用多个输入,那么可以通过两步流程来提升节省率:第一步使用费率较低但耗时较长的交易将多个小额输入整合为一个大额输入(资金依旧归属服务方);第二步则利用合并好的大额输入进行批量添加,以实现如上所述的最佳效率。
如果我们假设用于整合输入的交易只需支付常规交易 20% 的手续费率,并且每次可以整合 100 个输入,那么我们就可以推算在之前“1 个输入对应 1 个输出”这一场景下,采用两步流程会带来怎样的节省,并可将其与已经拥有大额输入(最佳情形)做对比。
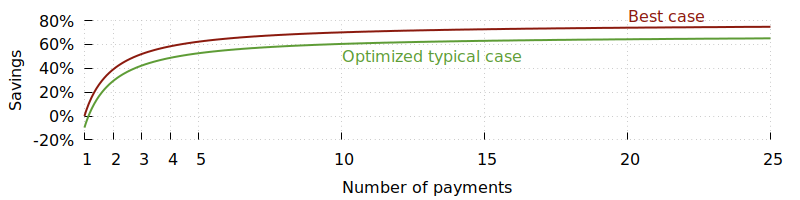
在这个常见情形中,如果只发送一笔支付,整合操作的效率会变低;但若合并发送多笔支付,其效果几乎能与最佳情形相当。
在直接提供手续费节省的同时,批量添加还通过减少每笔支付占用的 vbytes 来提升对区块空间的利用效率。这有助于提升单位时间内可处理的支付笔数,从而在需求恒定时降低用户发送比特币交易的成本。因此,更多地采用批量添加,有望让所有比特币用户的手续费率都变得更为低廉。
综上所述,当服务通常有 5~20 倍于单笔 typical output 的大额输入可用时,批量添加能提供显著的手续费节省;若不满足这一条件,仅仅依靠 batching 带来的节省可能有限,但仍值得尝试。如果服务愿意事先整合自己的输入,则节省率会非常可观。
注意:上述图表都基于 P2WPKH 输入与输出的假设。我们预计这一脚本类型会在未来(在出现更优技术之前)成为网络主流。不过,如果使用其他脚本类型(P2PKH,或者通过 P2SH 或 P2WSH 承载的多签),花费它们的 vbytes 更大,因此 batching 所实现的节省率也会更高。
注意事项
在享受批量添加带来的手续费降低的同时,也需要平衡并解决该技术本身带来的以下问题。
延迟
这是批量添加最大的问题所在。尽管部分情形能自然适配(如矿池在自己挖到的区块中一次性支付给算力提供者),但在许多情况下,用户需要接受:他们的支付并不会立即广播,而是被延后到一定时间后再与其他提现请求合并进行发送。
用户会注意到这一延迟:在你将他们的支付纳入批量交易并广播之前,他们的钱包不会出现任何未确认交易提示。此外,延迟广播交易也意味着交易得到确认的时间会顺延(若其他条件相同,如手续费率一致)。
为缓解这一问题,可以让用户在“即时广播”与“延期广播”两种选项中进行选择,并为每个选项提供不同的费用,例如:
[X] 免费提现(在 6 小时内发送交易) [ ] 立即提现(提现费 0.123 mBTC)
隐私性降低
批量添加的另一个问题在于它可能让用户感到隐私性降低。所有与他们同在一笔交易中的收款人都能大概率推断出,交易中的其他接收输出也都是来自同一家支付方。如果这些付款被拆分为多笔交易,彼此之间的链上关联可能会更难判定,甚至不存在关联性。

需要注意的是,对于部分比特币服务来说,其交易往往在专家眼中可被识别,就算不使用批量添加也如此,因此对这类用户来说,批量支付并不一定会带来更大的隐私损失。
或许可以结合 Coinjoin 机制,通过与他人共建交易的方式来部分缓解这一问题;在某些场景下,这样做不会削弱 batching 带来的效率,同时还能大大提升隐私。然而,一些服务商之前提供的 Coinjoin 功能实现过于简单,被发现存在缺陷,结果并未真正提高隐私。截至 2021 年 1 月,尚未有任何现有的 Coinjoin 实现完全兼容此类批量支付的需求。
可能无法手续费提升
最后一个问题在于,batched 交易可能无法进行手续费提升。比特币核心节点(Bitcoin Core)会针对传播的交易设置一些限制,以防止攻击者滥用节点资源(带宽、CPU 等)。单独来看,你不会轻易碰到这些限制,但是收款人可能会在交易尚未确认时花费他们收到的输出,从而产生新的子交易,并一并加入到包含你交易的交易组中。
在 Bitcoin Core 0.20(2020 年 6 月)中,针对相关交易组的限制是1:一组关联的未确认交易的总大小不可超过 101,000 vbytes,未确认祖先数量不可超过 25,后代数量也不可超过 25。对于一次性包含大量收款人的批量交易,如果收款人纷纷花费其未确认输出,可能很容易触达这一后代限制。
当交易组越逼近这些限制时,要使用 Child-Pays-for-Parent (CPFP) 或 Replace-by-Fee (RBF) 来给交易提高手续费便越困难。此外,若交易带有更多的未确认子交易,那么采用 RBF 提升手续费时就要额外为这些未确认子交易的可能性损失买单——矿工需要移除这组子交易以接受交易的替代版本。
这一问题并非批量支付所独有——分开的独立支付同样会遭遇类似情形。但差别在于,如果一笔独立支付因为收款人重花而导致无法手续费提升,只有该收款人受到影响;而若一个批量交易中的某一收款人花费了其输出并导致无法手续费提升,那么交易里其他所有收款人都会受到波及。如果他们知道你依赖这一提高手续费的能力,那么任何收款人都可以故意创建一些交易来让系统触达限制,从而实施交易固定攻击。
实现方式
如果使用特定现有钱包(例如 Bitcoin Core 的 sendmany RPC),实现批量添加非常容易。查看你所用软件的文档,寻找是否提供了发送多笔支付的功能接口。
bitcoin-cli sendmany "" '{
"bc1q5c2d2ue7x38hcw2ugk5q7y4ae7nw4r6vxcptu8": 0.1,
"bc1qztjzd7hpf2xmngr7zkgkxsvdqcv2jpyfgwgtsv": 0.2,
"bc1qsul9emtnz0kks939egx2ssa6xnjpsvgwq9chrw": 0.3
}'
如果在你自己的实现中使用,通常你已经在大部分场景下创建带有 2 个输出(收款人和找零)的交易,因此将更多收款人输出附加进去应该并不复杂。唯一需要注意的是,Bitcoin Core 节点(以及大多数其他节点)会拒绝接受或转发大小超过 100,000 vbytes 的交易,所以不应当尝试发送大于此限制的批量支付交易。
建议总结
-
尽量让系统中的用户或客户不要期望马上广播交易,而是愿意等待一段时间(时间窗口越长越好)。
-
使用低手续费率进行输入整合,并始终保持几个大额输入以便随时派发。
-
在每个延迟窗口内,将所有待支付请求一次性发送到同一个交易中。例如,可以设置一个按小时执行的 cronjob,将所有未决支付合并发送。理想情况下,之前的输入整合能保证此笔交易只需要一个输入。
-
不要依赖能够对批量交易做手续费提升。这意味着应当在最初交易中就设置足以保证在预期时间内成功确认的手续费率。例如,可以使 用 Bitcoin Core 的 estimatesmartfee RPC 的 CONSERVATIVE 模式。
注释
-
Optech 认为,几乎所有节点都采用 Bitcoin Core 对交易组限制的默认配置。不过,这些默认配置可能会随时间变化,所以下面的命令可用于检查当前限制以及对应的参数值。
$ bitcoind -help-debug | grep -A3 -- -limit -limitancestorcount=<n> Do not accept transactions if number of in-mempool ancestors is <n> or more (default: 25) -limitancestorsize=<n> Do not accept transactions whose size with all in-mempool ancestors exceeds <n> kilobytes (default: 101) -limitdescendantcount=<n> Do not accept transactions if any ancestor would have <n> or more in-mempool descendants (default: 25) -limitdescendantsize=<n> Do not accept transactions if any ancestor would have more than <n> kilobytes of in-mempool descendants (default: 101).