
/ home / newsletters /
Bulletin Hebdomadaire Bitcoin Optech #280
Le bulletin de cette semaine décrit plusieurs discussions sur le cluster mempool proposé et résume les résultats d’un test effectué à l’aide de warnet. Nous incluons également nos sections habituelles qui résument une réunion du Bitcoin Core PR Review Club, annoncent de nouvelles versions et des versions candidates, et décrivent les changements notables apportés aux principaux logiciels d’infrastructure Bitcoin.
Nouvelles
-
● Discussion sur le cluster mempool : Les développeurs de Bitcoin Core travaillant sur le cluster mempool ont lancé un groupe de travail (WG) sur le forum Delving Bitcoin. Le cluster mempool est une proposition visant à faciliter grandement les opérations sur le mempool tout en respectant l’ordre requis des transactions. Un ordre valide des transactions Bitcoin nécessite que les transactions parent soient confirmées avant leurs enfants, soit en plaçant le parent dans un bloc antérieur à tous ses enfants, soit plus tôt dans le même bloc. Dans la conception du cluster mempool, les clusters de une ou plusieurs transactions connexes sont conçus pour être divisés en morceaux triés par taux de frais. Tout morceau peut être inclus dans un bloc, jusqu’au poids maximum du bloc, tant que tous les morceaux non confirmés précédents (à taux de frais plus élevé) sont inclus plus tôt dans le même bloc.
Une fois que toutes les transactions ont été regroupées en clusters et que les clusters ont été divisés en morceaux, il est facile de choisir quelles transactions inclure dans un bloc : sélectionnez le morceau avec le taux de frais le plus élevé, suivi du suivant le plus élevé, et ainsi de suite, jusqu’à ce que le bloc soit plein. Lorsque cet algorithme est utilisé, il est évident que le morceau avec le taux de frais le plus bas dans le mempool est le morceau le plus éloigné d’être inclus dans un bloc, nous pouvons donc appliquer l’algorithme inverse lorsque le mempool devient plein et que certaines transactions doivent être supprimées : supprimez le morceau avec le taux de frais le plus bas, suivi du suivant le plus bas, et ainsi de suite, jusqu’à ce que le mempool local soit à nouveau inférieur à sa taille maximale prévue.
Les archives du WG peuvent maintenant être consultées par tous, mais seuls les membres invités peuvent publier. Certains sujets remarquables qu’ils ont discutés incluent :
-
● Définitions et théorie du cluster mempool définit les termes utilisés dans la conception du cluster mempool. Il décrit également un petit nombre de théorèmes qui mettent en évidence certaines des propriétés utiles de cette conception. Le seul message dans ce fil de discussion (au moment de la rédaction de cet article) est très utile pour comprendre les autres discussions du WG, bien que son auteur (Pieter Wuille) avertisse qu’il est encore “très incomplet”.
-
● Fusion de linéarisations incomparables examine comment fusionner deux ensembles différents de morceaux pour le même ensemble de transactions, spécifiquement des morcelages incomparables. En comparant différentes listes de morceaux, nous pouvons déterminer laquelle serait meilleure pour les mineurs. Les fragments peuvent être comparés si l’un d’entre eux accumule toujours la même quantité de frais ou plus dans n’importe quel nombre de vbytes (discret par rapport à la taille des morceaux). Par exemple :
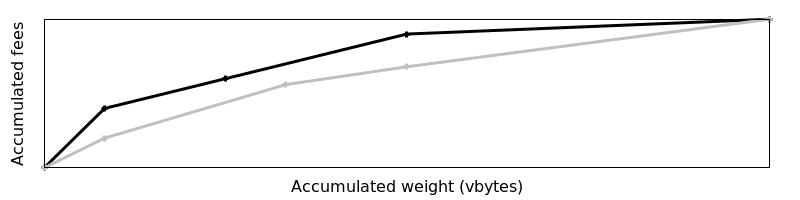
Les fragments ne sont pas comparables si l’un d’entre eux accumule un montant plus élevé de frais dans un certain nombre de vbytes, mais que l’autre accumule un montant plus élevé de frais dans un plus grand nombre de vbytes. Par exemple :
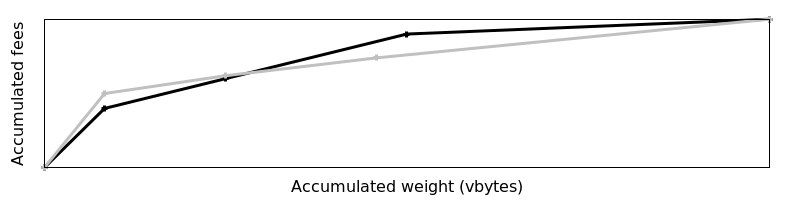
Comme l’un des théorèmes dans le fil précédemment lié le note, “si on a deux fragments incomparables pour un graphe, alors un autre fragment doit exister qui est strictement meilleur que les deux”. Cela signifie qu’une méthode efficace pour fusionner deux fragments incomparables différents serait un outil puissant pour améliorer la rentabilité des mineurs. Par exemple, une nouvelle transaction a été reçue qui est liée à d’autres transactions déjà dans le mempool, donc son cluster doit être mis à jour, ce qui implique également la mise à jour de son fragment. Deux méthodes différentes pour effectuer cette mise à jour peuvent être utilisées :
-
Un nouveau fragment pour le cluster mis à jour est calculé à partir de zéro. Pour les grands clusters, il peut être computationnellement impraticable de trouver un fragment optimal, donc le nouveau fragment pourrait être moins optimal que l’ancien.
-
Le fragment précédent pour le cluster précédent est mis à jour en insérant la nouvelle transaction dans un emplacement valide (parents avant enfants). Cela a l’avantage de préserver toutes les optimisations existantes dans les morceaux non modifiés, mais l’inconvénient est que cela pourrait placer la transaction dans un emplacement sous-optimal.
Après que les deux types de mises à jour différentes ont été effectuées, une comparaison peut révéler que l’une d’entre elles est strictement meilleure, auquel cas elle peut être utilisée. Mais si les mises à jour sont incomparables, une méthode de fusion garantie pour produire un résultat équivalent ou meilleur peut être utilisée à la place pour produire un troisième fragment qui capturera les meilleurs aspects des deux approches—en utilisant de nouveaux fragments lorsqu’ils sont meilleurs mais en conservant les anciens quand ils sont plus proches de l’optimal.
-
-
● Paquet post-cluster RBF discute d’une alternative aux règles actuellement utilisées pour replace by fee. Lorsqu’un remplacement valide d’une ou plusieurs transactions est reçu, une version temporaire de tous les clusters qu’il affecte peut être créée et leur fragment mis à jour peut être dérivé. Cela peut être comparé aux fragments des clusters d’origine qui sont actuellement dans le mempool (qui n’incluent pas le remplacement). Si le fragment avec le remplacement gagne toujours des frais égaux ou supérieurs à l’original pour n’importe quel nombre de vbytes, et s’il augmente le montant total des frais dans le mempool suffisamment pour payer ses frais de relais, alors il devrait être inclus dans le mempool.
Cette évaluation basée sur des preuves peut remplacer plusieurs heuristiques actuellement utilisées dans Bitcoin Core pour déterminer si une transaction doit être remplacée, améliorant potentiellement les règles RBF dans plusieurs domaines, y compris le relais de paquets proposé pour les remplacements. Plusieurs autres fils de discussions ont également discutés ce sujet.
-
-
● Test avec warnet: Matthew Zipkin a publié sur Delving Bitcoin les résultats de certaines simulations qu’il a réalisées en utilisant warnet, un programme qui lance un grand nombre de nœuds Bitcoin avec un ensemble défini de connexions entre eux (généralement sur un réseau de test). Les résultats de Zipkin montrent la mémoire supplémentaire qui serait utilisée si plusieurs modifications proposées du code de gestion des pairs étaient fusionnées (indépendamment ou ensemble). Il note également qu’il est enthousiasmé par l’utilisation de simulations pour tester d’autres modifications proposées et quantifier l’effet des attaques proposées.
Bitcoin Core PR Review Club
Dans cette section mensuelle, nous résumons une récente réunion du Bitcoin Core PR Review Club en soulignant certaines des questions et réponses importantes. Cliquez sur une question ci-dessous pour voir un résumé de la réponse de la réunion.
La réunion du Test de Bitcoin Core 26.0 Version Candidate du club de révision n’a pas examiné de PR particulier, mais a plutôt été un effort de test de groupe.
Avant chaque version majeure de Bitcoin Core, des tests approfondis par la communauté sont considérés comme essentiels. Pour cette raison, un volontaire rédige un guide de test pour une version candidate afin que le plus grand nombre de personnes possible puisse tester de manière productive sans avoir à déterminer indépendamment ce qui est nouveau ou modifié dans la version, et réinventer les différentes étapes de configuration pour tester ces fonctionnalités ou modifications.
Le test peut être difficile car lorsqu’on rencontre un comportement inattendu, on ne sait pas toujours s’il s’agit d’un bogue réel ou si le testeur commet une erreur. Il est inutile de signaler des bogues aux développeurs qui ne sont pas de vrais bogues. Pour atténuer ces problèmes et promouvoir les efforts de test, une réunion du Review Club est organisée pour un candidat à la version particulier, en l’occurrence 26.0rc2.
Le guide de test du candidat à la version 26.0 a été rédigé par Max Edwards, qui a également animé la réunion du club de révision avec l’aide de Stéphan (stickies-v).
Les participants ont également été encouragés à trouver des idées de test en lisant les notes de version 26.0.
Cette session du club de révision a couvert deux RPC, getprioritisedtransactions (également abordé
lors d’une réunion précédente du club de révision, bien que le nom de ce RPC ait été modifié après cette réunion
du club de révision) et importmempool. La section Nouveaux RPC des notes de version décrit ces RPC et d’autres
RPC ajoutés. La réunion a également abordé V2 transport (BIP324) et avait l’intention d’aborder
TapMiniscript, mais ce sujet n’a pas été discuté en raison de contraintes de temps.
-
Quels systèmes d’exploitation les gens utilisent-ils ?
Ubuntu 22.04 sur WSL (Windows Subsystem for Linux) ; macOS 13.4 (puce M1). ➚
-
Quels sont vos résultats en testant
getprioritisedtransactions?Les participants ont signalé que cela fonctionnait comme prévu, mais l’un d’entre eux a remarqué que les effets de
prioritisetransactionse cumulaient ; c’est-à-dire que l’exécution deux fois sur la même transaction doublait ses frais. C’est un comportement attendu, car l’argument des frais est ajouté à la priorité de transaction existante. ➚ -
Quels sont vos résultats concernant le test de
importmempool?Un participant a reçu l’erreur “Can only import the mempool after the block download and sync is done” mais après avoir attendu deux minutes, la RPC a réussi. Un autre participant a noté que cela prend beaucoup de temps pour se terminer. ➚
-
Que se passe-t-il si nous interrompons le processus CLI pendant l’importation, puis le redémarrons (sans arrêter
bitcoind)?Cela ne semble pas causer de problème ; la deuxième demande d’importation s’est terminée comme prévu. Il semble que le processus d’importation ait continué même après l’interruption de la commande CLI et que la deuxième demande n’ait pas (par exemple) provoqué l’exécution simultanée de deux threads d’importation et de conflits entre eux. ➚
-
Quels sont vos résultats concernant l’exécution du transport V2?
Les participants n’ont pas pu se connecter à un nœud principal connu activé pour V2 ; il ne semblait pas accepter la demande de connexion. Il a été suggéré que tous ses emplacements entrants étaient peut-être utilisés. Par conséquent, aucun test P2P n’a pu être effectué pendant la réunion. ➚
Mises à jour et versions candidates
Nouvelles versions et versions candidates pour les principaux projets d’infrastructure Bitcoin. Veuillez envisager de passer aux nouvelles versions ou d’aider à tester les versions candidates.
-
● Bitcoin Core 26.0 est la prochaine version majeure de l’implémentation principale du nœud complet. La version inclut une prise en charge expérimentale du protocole de transport version 2, la prise en charge de taproot dans miniscript, de nouvelles RPC pour travailler avec les états pour assumeUTXO, et une RPC expérimentale pour traiter les packages de transactions (qui n’est pas encore pris en charge pour le relais), parmi de nombreuses autres améliorations et corrections de bugs.
-
● LND 0.17.3-beta.rc1 est une version candidate qui contient plusieurs corrections de bugs.
Changements notables dans le code et la documentation
Changements notables cette semaine dans Bitcoin Core, Core Lightning, Eclair, LDK, LND, libsecp256k1, Interface Portefeuille Matériel (HWI), Rust Bitcoin, Serveur BTCPay, BDK, Propositions d’amélioration Bitcoin (BIPs), Lightning BOLTs, et Bitcoin Inquisition.
-
● Bitcoin Core #28848 met à jour la RPC
submitpackagepour être plus utile lorsque une transaction échoue. Au lieu de renvoyer uneJSONRPCErroravec la première erreur, elle renvoie les résultats de chaque transaction lorsque cela est possible. -
● LDK #2540 s’appuie sur le récent travail de chemin aveugle de LDK (voir les bulletins d’information #257 et #266) en prenant en charge le transfert en tant que nœud introducteur dans un chemin aveugle et fait partie du suivi du problème des offres BOLT12 de LDK.